СОДЕРЖАНИЕ
Как правильно кластеризовать семантическое ядро
Трюки при кластеризации с Excel
Кластеризация с помощью онлайн-сервиса Coolakov
Фокусы при кластеризации в Key Collector’е
У нас уже была статья про то, что такое семантическое ядро и как его собирать. Теперь пришло время разобраться с тем, что с этим семантическим ядром вообще делать. Каким бы большим (или маленьким) собранное ядро не оказалось, его необходимо разбить на логические группы, каждую из которых необходимо закрепить за отдельной страницей (созданной или нет – неважно). Собственно, процесс разделения семантического ядра на такие группы и принято называть кластеризацией (иногда называют просто «разбивкой»).
Как правильно кластеризовать семантическое ядро
Казалось бы, «ОК, разбиваем на логические группы, что тут непонятного-то?». А вот и нет! Как только дело доходит до дела – тут же появляется огромное множество вопросов по ключам, которые абсолютно не понятно в какие группы определять, поскольку они одновременно подходят под несколько групп, либо не подходят ни под одну имеющуюся.
Отсюда правило №1 – в каждой группе должен быть основной поисковый запрос, а остальные запросы должны быть его «модифицированными версиями»:
- туры бока чика
- туры в бока чика доминикана
- бока чика доминикана туры 2019
- купить тур в бока чика
- туры в доминикану бока чика
- путевки в доминикану бока чика
- доминикана бока чика туры цены
- путевки бока чика
- туры в бока чика из москвы
- отдых в бока чика доминикана цены
- туры в доминикану бока чика из москвы
Итак, в каких же модификациях у нас тут выступает основной ключ «туры бока чика»? Модификаций мало, к тому же нет ни одной модификации, которая поставила бы вопрос о целесообразности создания второй логической группы:
- + доминикана;
- + год (в данном случае – 2019);
- + купить;
- + цены;
- + москва.
Итак, ключи принципиально мало чем отличаются друг от друга, да и корректные Title, Description и H1 на их основе составить вполне реально. Также в некоторых ключах слово «тур» заменено на «путевку» или «отдых», т.е. на синонимы. Другой пример – ключи «отели бока чики для семейного отдыха» и «отели бока чики для отдыха с детьми». Эти ключи мы всегда объединяем, потому что семья без детей – это не семья, следовательно, в данном контексте «семейный отдых» и «отдых с детьми» тоже можно расценивать как синонимы.
Отсюда правило №2 – синонимайзинг в подобных случаях вполне допускается и даже приветствуется, поскольку создавать отдельные страницы про «туры», «путевки» и «отдых» - слишком абсурдно.
Усложним задачу и к вышеприведенному списку добавим еще один:
- горящие туры в бока чика
- доминикана бока чика горящие туры
- горящие путевки бока чика
Первое, что приходит в голову – объединить эти 2 списка, поскольку принципиальное отличие только в слове «горящие». Но есть и другой вариант – выделить эти ключи в отдельную логическую группу и закрепить ее за дополнительной страницей, поскольку далеко не все туры бывают «горящими». Какой же из этих вариантов будет самым правильным?
На этот вопрос нам поможет ответить Яндекс.Wordstat – смотрим частоту главного запроса второго списка, а также смотрим историю частот запросов. В нашем случае все 3 ключа даже в «пик сезона» являются низкочастотными, поэтому оба списка можно объединить. Но встает вполне разумный вопрос: поскольку «туры» и «горящие туры» - это не совсем одно и то же, то корректно составить Title, Description и H1 с таким набором ключей уже не получится. Может всё-таки разделить?
Если бы вторая группа ключей имела хотя бы средние частоты, то мы бы так и сделали. Ну а поскольку ключи низкочастотные, то можно ограничиться H2-подзаголовком, который в поисковой выдаче Яндекса вполне может быть выведен вместо Title. Да-да, мы не шутим, Яндекс в сниппетах иногда указывает H2-подзаголовок. Вот пруф.
Обратите внимание, что в конце заголовка стоит точка – это очень важная в данном кейсе мелочь.
Теперь заходим на страницу и смотрим Title:

Как видите, Title вообще не сходится с заголовком, который был выведен в сниппет поисковой выдачи Яндекса. Давайте посмотрим H1-заголовок.
И снова мимо. ОК, листаем дальше и…
Мы видим текст сверху и текст снизу, т.е. это никак не может быть H1-заголовок. Остается только H2. Плюс к этому, в конце заголовка тоже стоит точка.
Т.е. тот факт, что в данном случае Яндекс в сниппете показал не Title, а H2-подзаголовок, доказан на все 146%.
Отсюда правило №3 – объединение двух логических групп допускается только в том случае, если можно обойтись одним дополнительным H2-подзаголовком. Если дополнительных H2-подзаголовков будет два – группы лучше не объединять.
Усложним задачу и к уже имеющимся двум спискам (да-да, в данную секунду мы будем их рассматривать как 2 отдельных списка, а не как один объединенный) добавим ключ «горящие туры в бока чика на новый год».
И вот тут Вы уже и сами догадались, что:
- ранее упоминавшиеся 2 списка при таком раскладе объединять не стоит;
- выделять отдельную страницу под «новый год» тоже не стоит.
Остается только 1 вариант – самый правильный:
- «туры» - отдельно, а «горящие туры» - отдельно;
- «новый год» объединить с «горящими турами», а также сделать отдельный H2-подзаголовок.
Отсюда правило №4 – никогда не бойтесь анализировать ситуацию «на лету» - это реально спасает.
И вот на последнем примере возникает вполне логичный вопрос – а что делать, если аналогичных «новогодним» ключам много?
ОК, давайте «до кучи» добавим еще несколько:
- горящие туры в бока чика на апрель;
- горящие туры в бока чика на август;
- горящие туры в бока чика на зиму.
Что делать? Правильно – объединять их с «горящими» и делать соответствующие подзаголовки при подготовке текста-описания страницы.
Ну и еще один пример, на этот раз совсем на другую тематику. Есть сайт https://vape.academy/ - это наш клиент. Недавно нам была поставлена задача – собрать ядро по кальянным табакам и сделать его кластеризацию. В ядре были ключи:
- табак бекон
- табак со вкусом бекона
- табак для кальяна бекон
- табак для кальяна со вкусом бекона
Вполне очевидно, что все 4 ключа должны быть в одной логической группе. Именно так мы и поступили, но дальше начинается самое интересное. Страницы, за которой можно было бы закрепить данную группу, на сайте нет. В то же время на сайте на данный момент всего 3 карточки с подходящими товарами, т.е. создавать для них дополнительную страницу особого смысла нет.
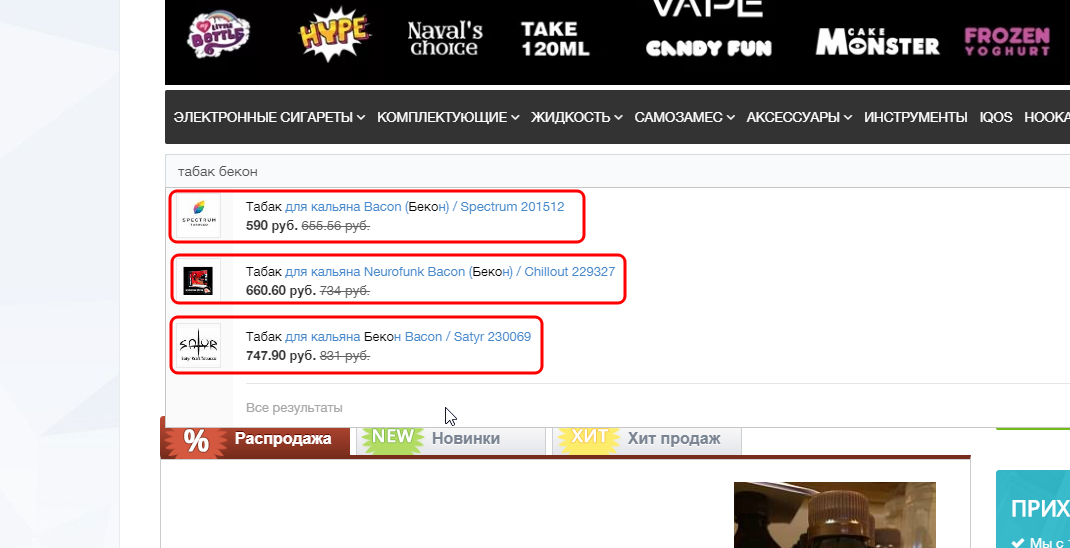
Т.е. страницы нет, а создавать ее ради трёх карточек – бесполезно, с таким ассортиментом точно не выстрелит.
Решение оказалось предельно простым – закрепить данную группу за всеми тремя карточками. И мы бы его применили, если б не одно небольшое НО – заказчик пояснил, что ассортимент в ближайшее время будет расширяться и другие табаки со вкусом бекона тоже появятся. Это была единственная причина, по которой данный список ключей был закреплен за дополнительной страницей. Если б заказчик этого не сказал – мы бы так не поступили.
Отсюда правило №5 – некоторые ключи (а в данном примере – всю логическую группу) можно (а иногда – крайне необходимо) закреплять сразу за несколькими страницами.
Другой пример по этой же тематике и с этим же заказчиком. Есть два ключа:
- табак для кальяна вафли
- бельгийская вафля табак для кальяна
На первый взгляд очевидно, эти ключи должны быть объединены. Однако, в данном случае эти 2 ключа были разделены не просто на 2 логические группы, а на 2 логические группы, в каждой из которых всего по 1 ключу. Зачем? А вот зачем.
Пруф 1 – в магазине предостаточно табаков со вкусом вафли, чтобы выделить данный ключ в отдельную логическую группу для дополнительной страницы:
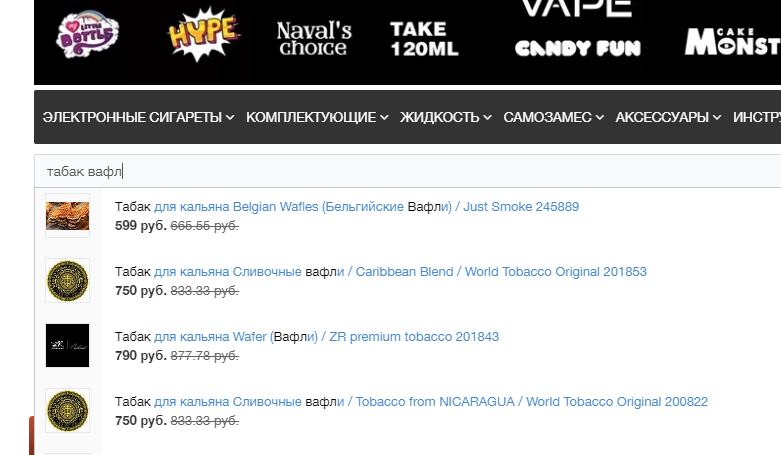
Пруф 2 – в магазине всего ОДИН табак со вкусом бельгийской вафли:
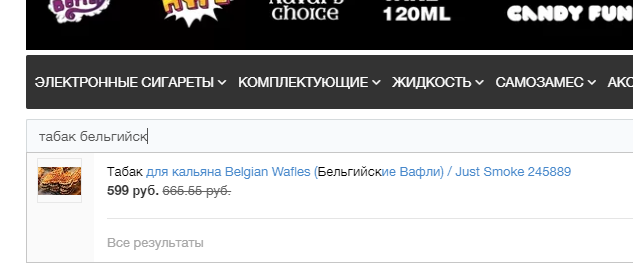
Создавать дополнительную страницу ради одной карточки товара – абсурд. Объединять бельгийскую вафлю с обычной в одну группу, а на странице выделять бельгийскую вафлю подзаголовком – ровно такой же абсурд. Поэтому здесь возможно только одно решение: вафля отдельно, а бельгийская вафля отдельно, причем с закреплением на вполне конкретную карточку товара.
Отсюда правило №6 – в логической группе может быть любое количество ключей (кроме нуля, отрицательных и дробных чисел). На нашей практике бывали случаи, когда приходилось формировать логическую группу из 50-70 ключей, поскольку все они были практически однотипные.
Итак, основные правила кластеризации мы рассмотрели. Теперь переходим к самой «механике». И вот тут начинается самое интересное.
Виды кластеризации
На сегодняшний день существует всего 2 вида кластеризации – автоматическая и ручная.
Как Вы уже догадались, ручная кластеризация – это способ, при котором сортировка семантического ядра производится полностью вручную. Данный способ является самым точным, поскольку тут всего один фактор – человеческий. Как правило, ручная кластеризация делается через Excel.
С автоматизированной кластеризацией всё немного иначе.
Во-первых, она выполняется в автоматическом режиме либо с помощью специального программного обеспечения, либо с помощью онлайн-сервисов.
Во-вторых, автоматизированная кластеризация никогда не бывает точной, а это значит, что ее в любом случае придется «допиливать» вручную. Зато так экономится достаточно большое количество времени, особенно в те моменты, когда семантическое ядро состоит из нескольких тысяч поисковых запросов. Хотя… Тут уже зависит всё от того, насколько грамотно была сделана кластеризация, ибо нередки случаи, когда «на автомате» выдается такая бредятина, что проще сделать с нуля, чем допиливать результат работы искусственного интеллекта.
Следовательно, ручная может существовать без автоматизированной только на очень маленьких объемах, а автоматизированная без ручной существовать вообще никак не может.
Автоматизированная кластеризация может осуществляться как с помощью платных, так и с помощью бесплатных онлайн-сервисов или программ.
В рамках данной статьи будут рассмотрены:
- программа Key Collector (платная);
- онлайн-сервис Coolakov (условно бесплатный);
- рассмотрим несколько трюков в Excel.
По идее в списке должна быть еще и программа KeyAssort (платная), но ее обзор будет вынесен в отдельную статью, как это уже было сделано с Key Collector’ом (обзор выпущен в двух частых – первая и вторая).
С ручной и автоматической кластеризацией разобрались. Автоматическая же кластеризация дополнительно подразделяется на Soft и Hard.
Soft-кластеризация представляет собой сравнение основного запроса группы со всеми остальными. Т.е. производится сборка ТОП-10, а потом происходит сравнение количества совпадающих в выдаче адресов между основным запросом и всеми остальными.
Hard-кластеризация представляет то же самое, но список УРЛов, добытых из ТОП-10 Яндекса, сравнивается уже не с основным запросом, а со всеми запросами группы.
Есть еще и третья методика – Middle-кластеризация, являющаяся «гибридом» двух остальных.
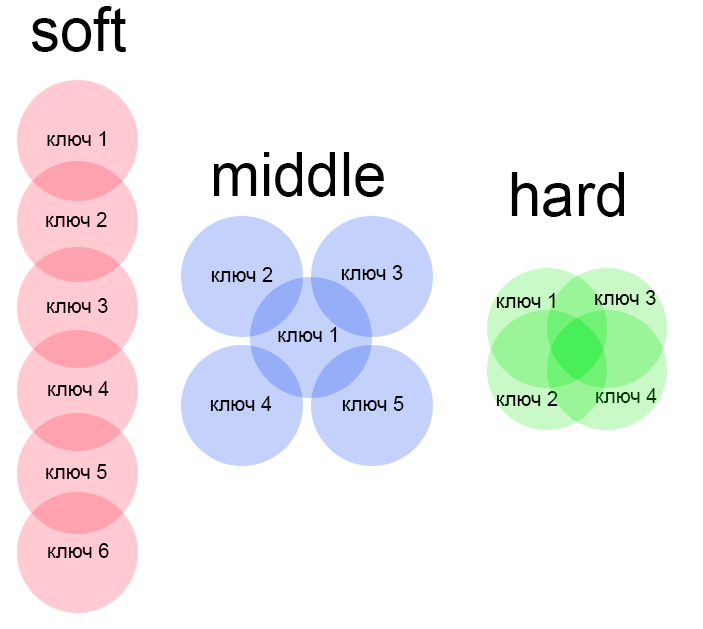
Схематически это будет выглядеть примерно вот так:
У каждой кластеризации свои плюсы и минусы, а именно:
- Soft формирует более крупные кластеры, но чаще ошибается;
- Hard ошибается, но формирует более мелкие кластеры, которые (не всегда, но достаточно часто) по интенту всё-таки можно объединить между собой.
Именно поэтому:
- Soft-методика, как правило, используется для кластеризации ядра интернет-магазинов с простой структурой каталога, а также для блога;
- Hard-методика, как правило, используется для кластеризации ядра сайта организации, оказывающей какие-либо сложные, но в то же время популярные коммерческие услуги (микрозаймы, автокредиты, страхование, и т.д.).
С видами кластеризации мы разобрались, теперь переходим от теории к практике.
Трюки при кластеризации с Excel
Начнём с полностью ручной методики, ибо в любом случае именно с нее придется начинать, если захотите познать искусство кластеризации.
Как видите, ничего суперсложного – просто окрашиваем ячейки, а затем сортируем по окрасу. Далее окрашенные ячейки выносим на отдельный лист, анализируем, убираем лишнее, при необходимости добавляем логические группы, а затем возвращаемся к основному ядру и продолжаем разбивать ядро до тех пор, пока оно не закончится.
Данный способ бесполезен, если в списке всего 80-100 ключей (в узкоспециализированных нишах такое вполне возможно), т.к. их проще и быстрее кластеризовать «на глаз», и крайне полезен, если требуется вручную рассортировать ядро объемом в несколько сотен ключей. Если счёт идёт на тысячи ключей, то сэкономленного времени будет еще больше, однако, сортировка такого ядра в любом случае займёт, скажем так, не один рабочий день. Поэтому данный способ подходит только для объёма от 200 до 1500-2000 ключей, не более.
Кластеризация с помощью онлайн-сервиса Coolakov
Итак, мы добрались до онлайн-сервиса от Евгения Кулакова - http://coolakov.ru/tools/razbivka/.
Это условно бесплатный сервис, позволяющий кластеризовать ядра объёмом до 1000 ключей (на данный момент).
Как видите, данный онлайн-сервис показал себя очень даже сносно – да, есть небольшие косяки, которые буквально сразу бросаются в глаза, но сама процедура кластеризации в итоге заняла порядка 2 минут, а это очень быстро.
Также мы настоятельно рекомендуем всем, кто пользуется данным онлайн-сервисом, делиться с Евгением Кулаковым своими XML-лимитами. Этот сервис нужен нам всем, а без нас ему просто не выжить.
Фокусы при кластеризации в Key Collector’е
У нас уже есть одно видео, в котором мы рассказываем о том, что в данной программе есть необходимый для кластеризации поисковых запросов функционал. Однако, там мы его использовали не для кластеризации, а для очистки семантического ядра. Сегодня же мы поговорим именно о кластеризации.
Основной минус кластеризации с помощью Key Collector’а заключается в том, что сбор необходимых данных из поисковых систем отнимает достаточно много времени. Поэтому данный способ абсолютно не подходит для больших ядер, если Вы не используете прокси-серверы.
Однако, само по себе семантическое ядро можно собрать таким образом, что кластеризация не особо-то и потребуется, ибо собранные поисковые запросы будут кластеризованы уже заранее.
Основной минус такой методики в том, что она не универсальна. Например, если Вы впервые будете собирать семантическое ядро по ракетным двигателям, то вряд ли Вы будете заранее знать, какие логические группы вообще могут быть в данной сфере. Тем не менее, для туристической тематики данная методика очень даже подходит.
Итоги
Итак, что же мы имеем?
Мы разобрались с тем, что вообще представляет собой кластеризация семантического ядра, разобрались, какая она вообще бывает, а также разобрались в том, чем ручная кластеризация лучше автоматизированной и чем автоматизированная лучше ручной. Ну а в качестве бонуса мы рассмотрели 3 неплохих инструмента:
- Excel (который есть у каждого);
- Key Collector (который стоит 800 рублей за пожизненную лицензию);
- сервис Евгения Кулакова (до 1000 ключей за 1 заход – бесплатно).
В реальной же жизни этих инструментов гораздо больше:
- онлайн-сервис PromoPult (платно);
- онлайн-сервис TopVisor (тоже платно);
- программа KeyAssort (1900 рублей за пожизненную лицензию)
И т.д.
Т.е. рассказать очень даже есть о чём – как минимум о KeyAssort, ибо она достойна отдельной статьи.





