СОДЕРЖАНИЕ
Стандартная формула расчета KEI в KeyCollector
KEI: вычисление эффективности ключевой фразы по шкале 0 до 100
KEI: вычисление уровня конкуренции по ключу
Сбор рекомендаций на внутреннюю перелинковку с помощью Key Collector
Итак, продолжаем разбирать программу KeyCollector. В прошлой части мы достаточно много внимания уделили сбору семантического ядра и его очистке. В этой же части мы уделим большое внимание формулам KEI.
Для тех, кто не в курсе, KEI расшифровывается как Keyword Effectiveness Index, т.е. индекс эффективности ключа. Хотя, если посмотреть правде в глаза, то формулы KEI можно конфигурировать как угодно, т.е. какого-либо универсального рецепта формулы здесь нет и быть не может.
Для начала давайте рассмотрим, где вообще хранятся формулы для вычисления KEI. Заходим в Настройки – KEI & SERP и видим вот это:
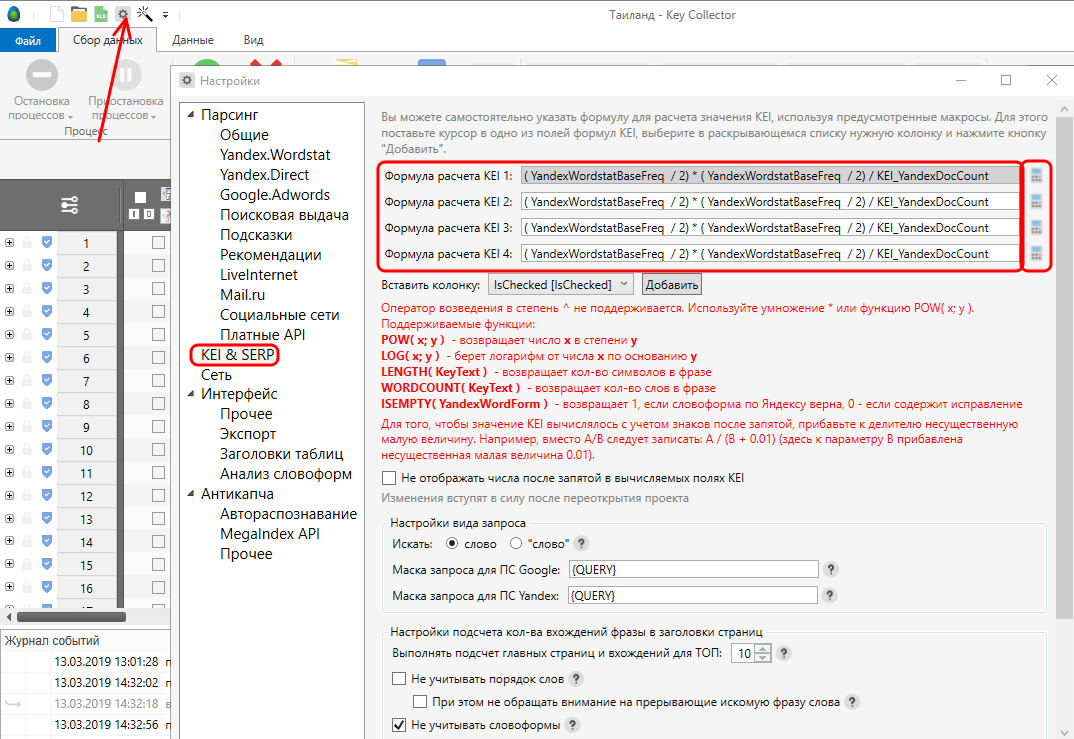
Здесь мы видим 4 поля, в которых хранится одна и та же «штатная» формула для расчета KEI. Справа от этих четырех полей есть 4 калькулятора, с помощью которых можно вычислить KEI не по всем формулам сразу, а по какой-то одной конкретной формуле.
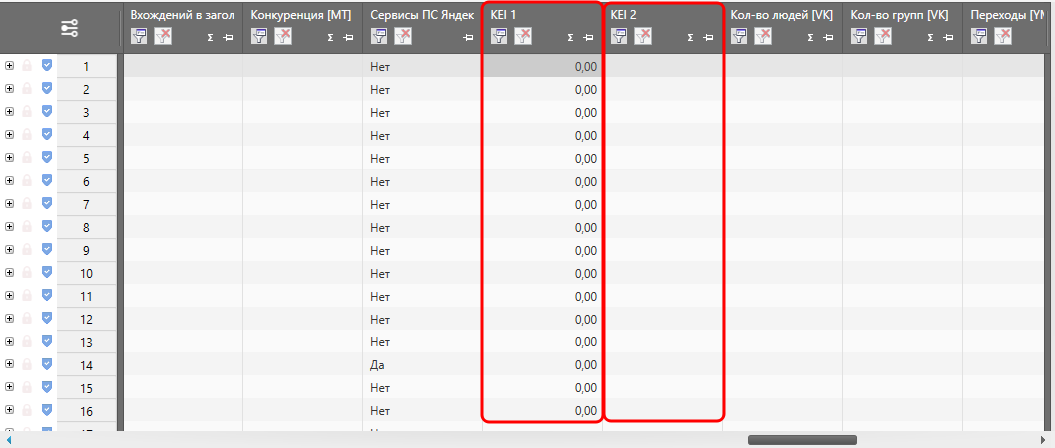
Данные, полученные в результате вычислений, выводятся в таблицу в соответствующие колонки:
Чуть ниже мы будем рассматривать несколько формул и у Вас наверняка возникнет вопрос, «А откуда Вы переменные-то берёте? И откуда Вы знаете, какая переменная за что отвечает?». Вот отсюда:
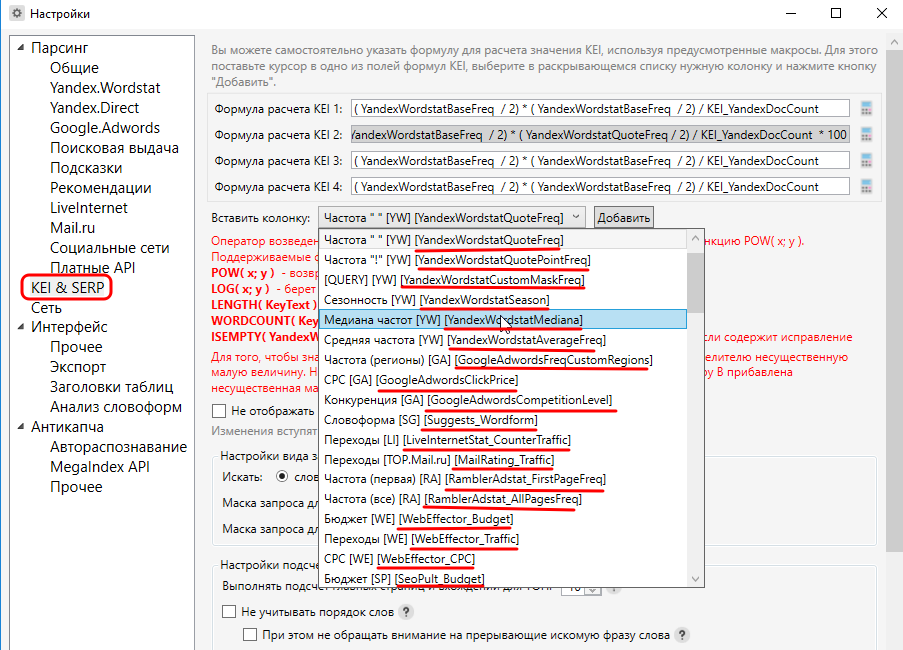
Стандартная формула расчета KEI в KeyCollector
Выглядит эта формула - вот таким образом:
( YandexWordstatBaseFreq / 2) * ( YandexWordstatBaseFreq / 2) / KEI_YandexDocCount
Расшифруем переменные:
YandexWordstatBaseFreq – это базовая частота по Яндексу
KEI_YandexDocCount – сколько документов ранжируется в Яндексе по данному запросу.
Т.е. в переводе на русский язык получаем следующую формулу: базовая частота по Яндексу делится пополам, полученное число возводится в квадрат, а затем делится на количество ранжируемых документов. Следовательно, чем выше базовая частота – тем выше KEI, а чем выше конкурентность (т.е. количество документов в поисковой выдаче) – тем ниже KEI. Тот случай, когда «чем больше – тем лучше». Или нет? Ведь другие 2 вида частот не учитываются, а потому запрос вполне может оказаться накрученным, верно?
К тому же, стандартная формула вполне может выдать нули, т.е. по данным запросам якобы продвигаться нет смысла. Давайте посчитаем вручную. Для этого возьмём первую строку. Базовая частота запроса составляет 1293 показов.
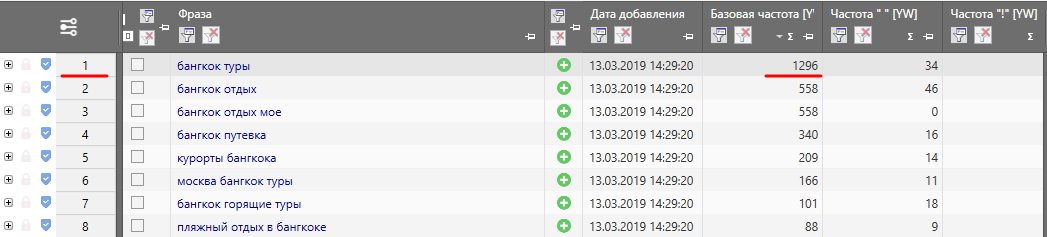
Считаем по формуле:
1) 1293 / 2 = 646,5
2) 646,5 * 646,5 = 417962,25
3) 417962,25 / 98000000 = 0,004264921
Откуда мы взяли 98000000? Очень просто – мы пробили позиции по сайту, а Вы уже знаете, что помимо позиций Key Collector собирает еще ряд данных.
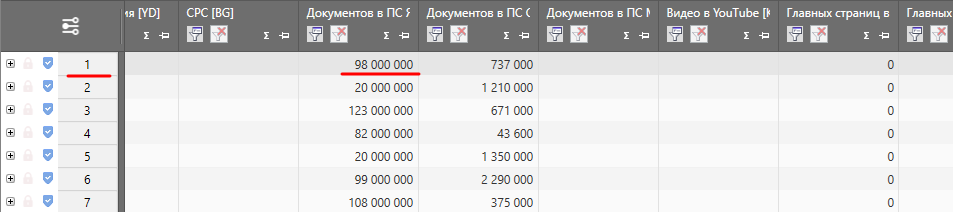
Т.е. то что KEI в итоге равен 0,00 – мы по сути то же самое и получили. Но при этом мы с Вами понимаем, что «что-то тут не то, не может быть такого, чтобы по этому ключу не было смысла продвигаться».
Отсюда простейший вывод – от стандартной формулы, которая указана в Кей Коллекторе, толку крайне мало. Однако, никто не мешает нам разработать более информативную формулу, верно? Верно. Этим и займёмся.
Для начала во вторых скобках заменим базовую частоту на частоту в кавычках, а количество документов в поисковой выдаче разделим на 1 миллион, чтобы у нас не получались слишком маленькие числа. Новая формула теперь выглядит вот так (изменения отмечены красным):
( YandexWordstatBaseFreq / 2) * ( YandexWordstatQuoteFreq / 2) / ( KEI_YandexDocCount / 1000000)
Считаем:
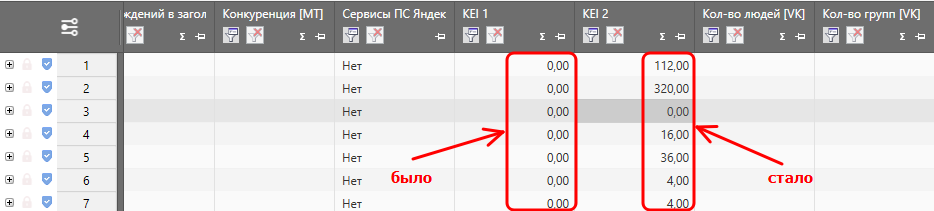
Эффективность по-прежнему измеряется по принципу «чем больше – тем лучше», плюс в вычислении KEI задействовано больше величин. Да и KEI перестал быть нулевым, теперь можно хотя бы чуть-чуть сориентироваться в том, какие ключи наиболее эффективны для продвижения.
Можно модифицировать формулу еще раз, добавив домножение на половину «!частот», и т.д. Можно модифицировать формулы как угодно на своё усмотрение.
В качестве примера рассмотрим еще несколько формул.
KEI: вычисление эффективности ключевой фразы по шкале 0 до 100
Вот таким образом выглядит формула:
((YandexWordstatBaseFreq + YandexWordstatQuotePointFreq) / (YandexWordstatBaseFreq + 0.01) — 1 ) * 100, где:
YandexWordstatBaseFreq – базовая частота
YandexWordstatQuotePointFreq – «!частота»
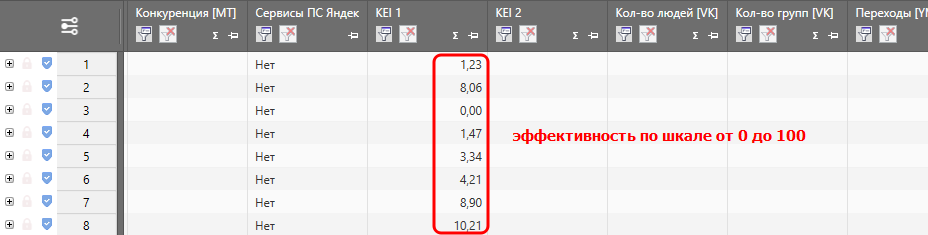
Соответственно, чем выше KEI – тем эффективнее ключевая фраза. Минус формулы в том, что в ней не учитывается сезонозависимость (у сезонозависимых запросов эффективность меняется от сезона к сезону) и количество документов в поисковой выдаче. Но зато помогает буквально в 1 клик выявить запросы, по которым продвигаться бессмысленно.
KEI: прогноз объёма трафика
ВАЖНО!!! Сейчас речь идет именно об органической выдаче, а не о рекламной! Следовательно, и трафик будет поисковый, а не рекламный. В данном подразделе статьи мы рассмотрим сразу 2 формулы.
Начнём вот с этой - (YandexWordstatQuotePointFreq) * X + 0.01, где:
YandexWordstatQuotePointFreq – «!частота» по Яндексу
X – значение, которое будет меняться в зависимости от позиции сайта:
ТОП-1 (т.е. самая высокая позиция сайта) = 0,25
ТОП-2 = 0,15
ТОП-3 = 0,1
ТОП-4 = 0,08
ТОП-5, ТОП-6, ТОП-7 = 0,04
ТОП-8, ТОП-10 = 0,03
ТОП-9 = 0,02
Почему именно эти цифры? Очень просто – если домножить эти коэффициенты на 100, то мы получим приблизительный среднестатистический процент распределения посетителей по ТОП-10. Т.е. если необходимо спрогнозировать трафик по какой-то конкретной позиции, то просто подставляем вместо X нужный коэффициент и получаем приблизительный прогноз трафика.
Данную формулу, как Вы уже поняли, нельзя назвать точной, т.к. при попадании в ТОП-1 далеко не всегда на сайт приходит именно 30% посетителей, может быть и меньше. Например, когда на странице выдачи большое количество рекламы, из-за чего ТОП-1 физически не помещается на экран. Взгляните вот на этот скриншот. Он сделан при разрешении экрана 1920х1080 пикселей.
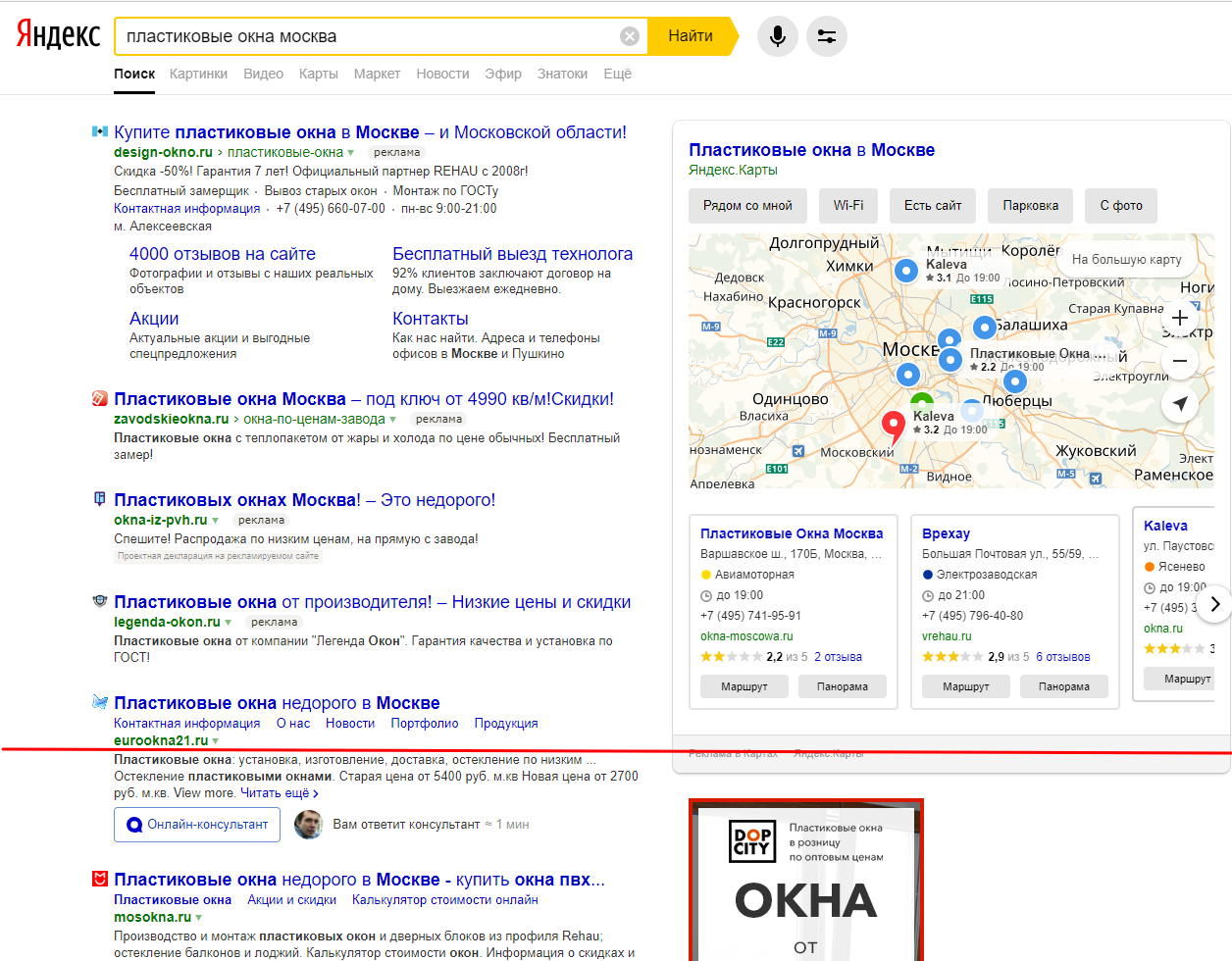
Если перенастроить разрешение на 1366х768 (а это самое популярное на сегодня десктопное разрешение экрана), то на первый экран НЕ попадёт, то, что находится ниже красной черты. Не верите? С помощю браузера Opera сэмулировать такое разрешение не составит труда.
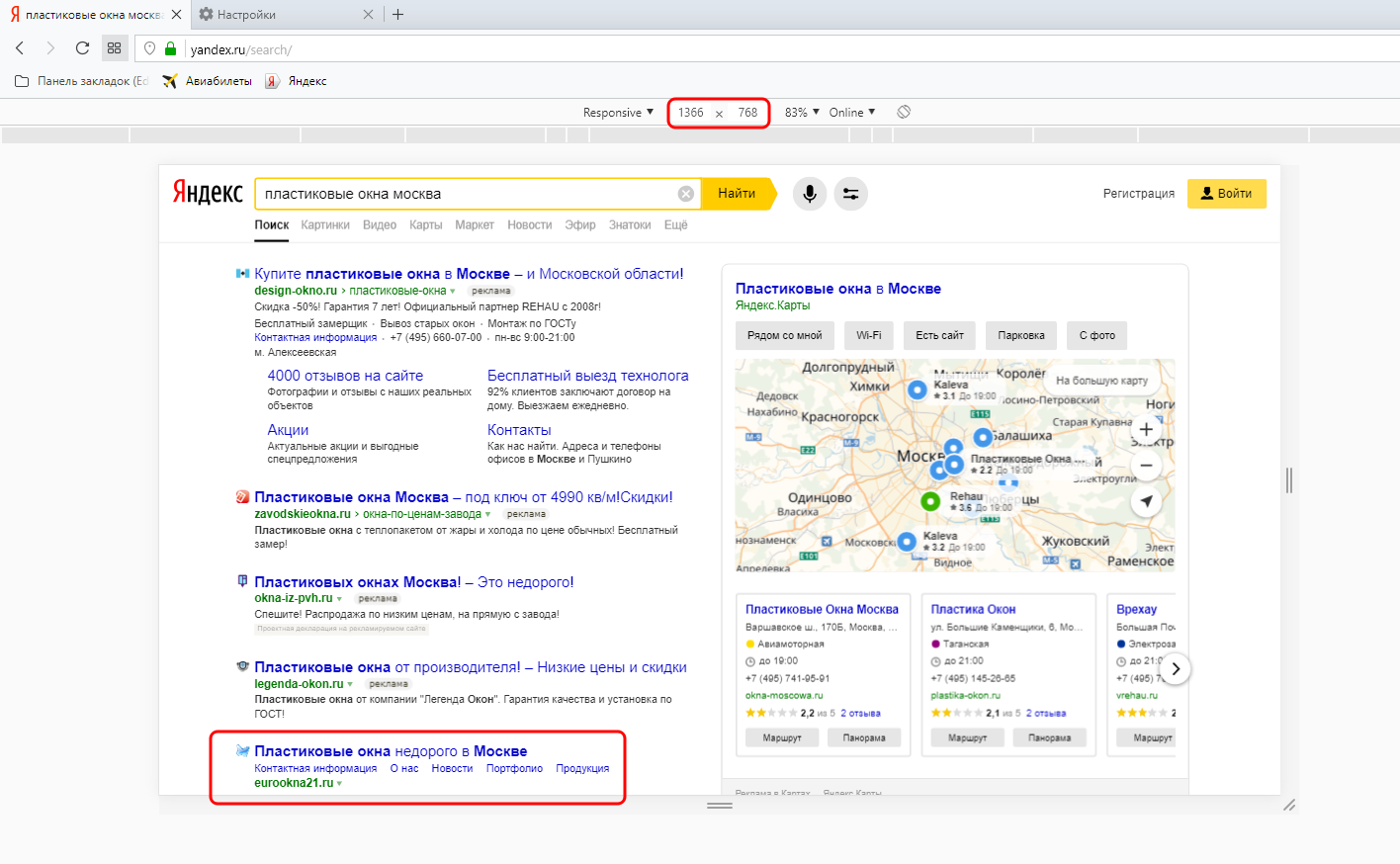
Т.е. в большинстве случаев на первый экран у нас попадает только ТОП-1, и то сниппет помещается не полностью (не попали Description и кнопка онлайн-чата). Становится очевидно, что почти 60% трафика отхапают себе именно рекламные объявления, а потому гораздо правильнее полученный KEI домножить на оставшиеся 40%. Т.е. конкретно для запроса «пластиковые окна москва» формула расчета прогноза посещаемости будет выглядеть не вот так:
( YandexWordstatQuotePointFreq ) * 0,25 + 0.01
а вот так:
(( YandexWordstatQuotePointFreq ) * 0,25 + 0.01 ) * 40 / 100
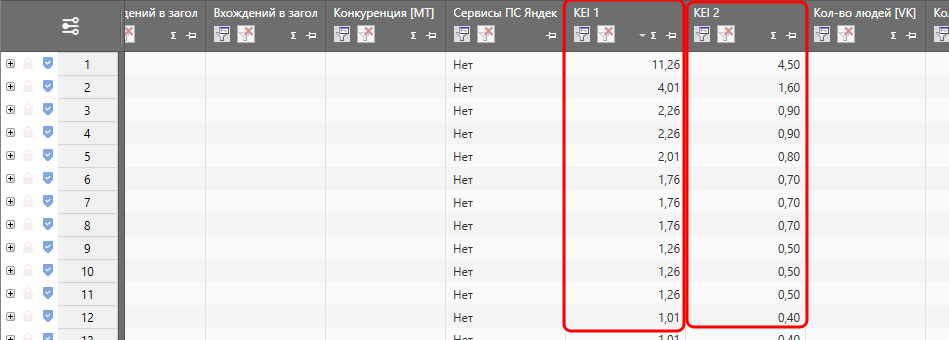
Результаты будут в корне отличаться:
(первая формула – KEI 1, вторая – KEI 2)
Теперь переходим к другой формуле:
( YandexWordstatQuotePointFreq ) * (((15 + 10 + 8 + 4 + 0.01 ) / 4 ) / 100 )
С ее помощью можно спрогнозировать трафик, если сайт по запросу попадёт в ТОП-5 (за исключением первой позиции). Естественно, если по ключу вылезает куча рекламных объявлений, практически вытесняющих органическую выдачу вниз, то результат тоже имеет смысл домножить на 40% для более точного прогноза.
KEI: вычисление уровня конкуренции по ключу
Здесь рассмотрим сразу две формулы.
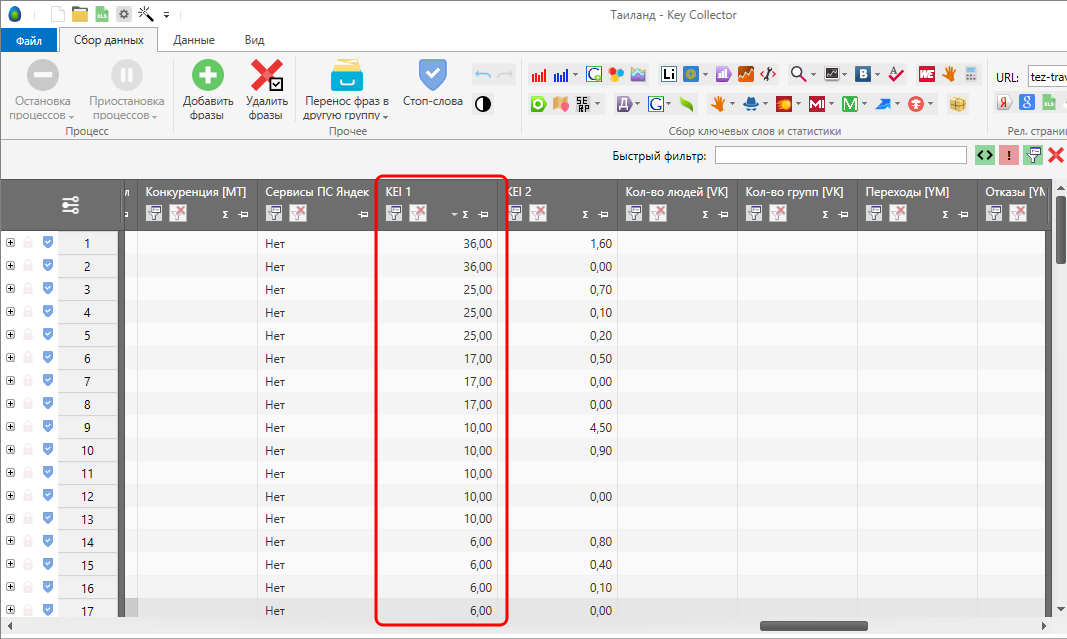
Для Яндекса – (( KEI_YandexMainPagesCount * KEI_YandexMainPagesCount * KEI_YandexMainPagesCount ) + ( KEI_YandexTitlesCount * KEI_YandexTitlesCount * KEI_YandexTitlesCount )) / 20
Для Google – (( KEI_GoogleMainPagesCount * KEI_GoogleMainPagesCount * KEI_GoogleMainPagesCount ) + ( KEI_GoogleTitlesCount * KEI_GoogleTitlesCount * KEI_GoogleTitlesCount )) / 20.
Т.е. главные страницы в кубе + количество точных вхождений фраз в заголовки в кубе.
Кстати, в куб потребовалось возводить для более высокой точности. Откуда взялось 20? Очень просто. Допустим у нас в ТОП-10 находится 10 главных страниц, на каждой из которых есть точное вхождение ключа. 10 в кубе = 1000, итого 1000+1000=2000 – это максимальное значение результата вычислений. Если же разделить на 20, значение будет варьироваться от 0 до 100. Можно сказать, что уровень конкуренции в этом случае будет вычисляться в процентах.
Key Collector для YouTube
На данный момент Key Collector для YouTube-блогеров не особо полезен. Во-первых, невозможно отмониторить позиции своего видео по тому или иному поисковому запросу, поскольку выдача формируется индивидуально для каждого с учётом интересов, к тому же она не является единственным источником просмотров.
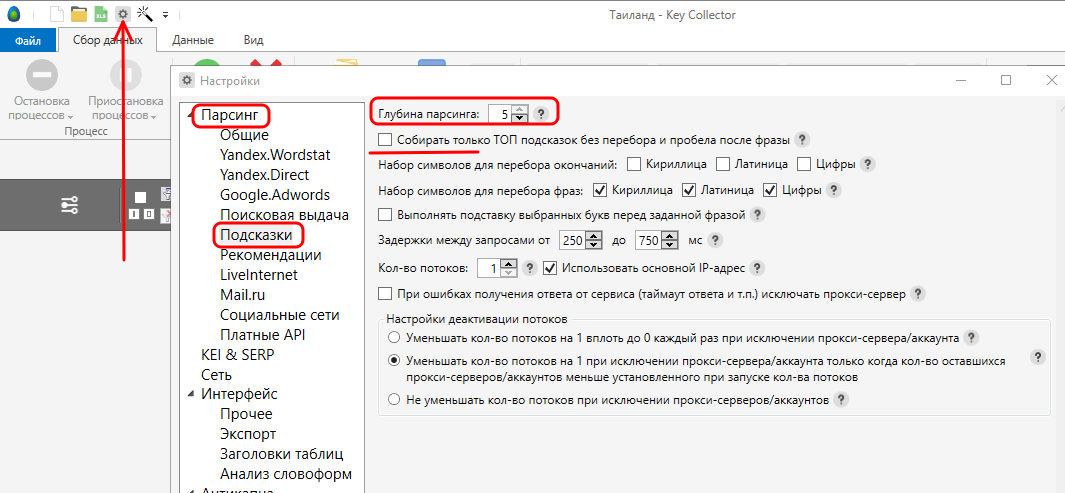
Поэтому самый максимум, чем может быть полезен Key Collector для YouTube-блогеров – помощь в парсинге поисковых подсказок. Для этого надо Key Collector немного перенастроить.
Заходим в Настройки – Парсинг - Подсказки, выставляем максимальную глубину (5) и снимаем галочку «Собирать только ТОП».
Затем заходим в Поисковые подсказки, из галочек оставляем только YouTube и Safe-режим, прописываем интересующие ключи и запускаем парсинг.
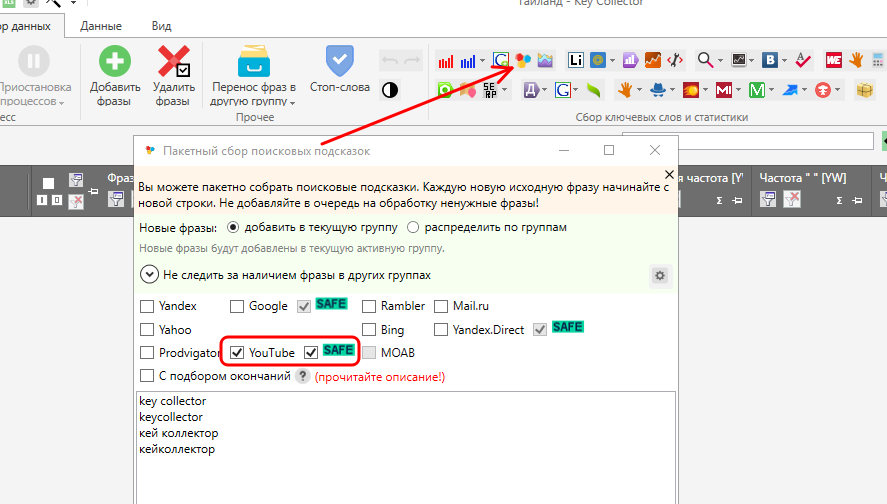
На выходе Вы получите список поисковых подсказок от YouTube.
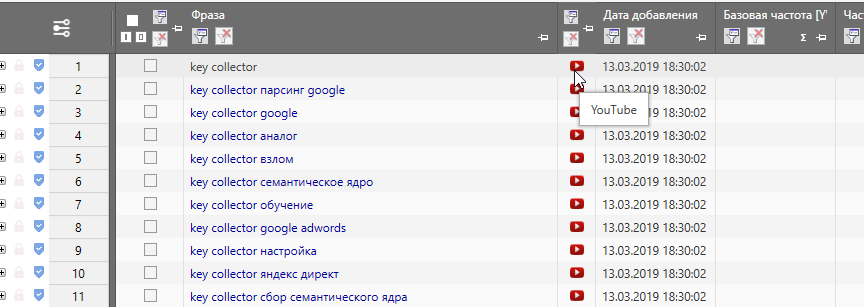
За счет данных подсказок можно быстро сформировать заголовок, описание и теги продвигаемого видео и получить хороший прирост просмотров.
Сбор рекомендаций на внутреннюю перелинковку с помощью Key Collector
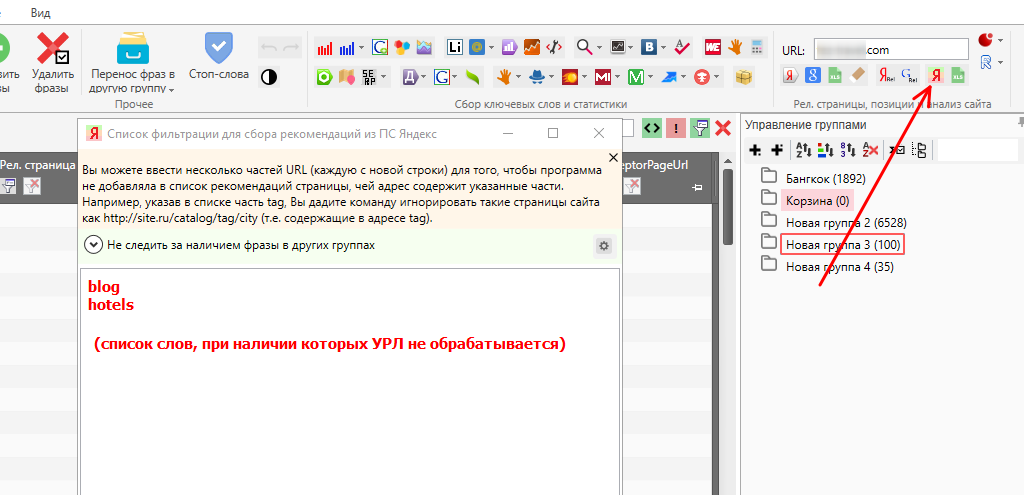
Да, с помощью Key Collector’а можно собирать рекомендации на внутреннюю перелинковку. Собственно, кроме списка ключей и УРЛ сайта для этих целей больше ничего не требуется. Т.е указываем УРЛ сайта, нажимаем кнопку сбора рекомендаций, в открывшемся окне (при необходимости) добавляем список «обрезков» и запускаем сбор рекомендаций.
На счет «обрезков» сейчас объясним. Если в список добавить blog, то будут игнорироваться все УРЛ, в которых присутствует данный «обрезок».
На выходе мы получим список УРЛ, наиболее подходящих в качестве акцептора (приемника), т.е. именно на эти страницы лучше всего ссылаться по соответствующим ключам (1 страница = 1 ключ). Список этих УРЛ будет находиться в таблице в столбце AcceptorPageURL.
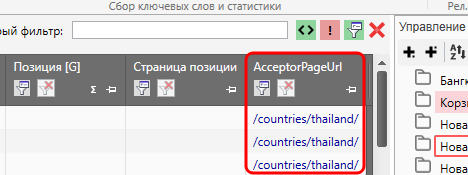
НО… Эти данные НЕ панацея, т.е. это рекомендации, сделанные на основе поисковой выдачи. Т.е. эти данные необходимо проверять, т.к. не факт, что на сайте вообще существует релевантная данному запросу страница. Если ее на самом деле на сайте нет, то и ссылаться, соответственно, не на что. Однако, это не значит, что поле в этом случае будет пустым.
Играемся с интерфейсом
По умолчанию в таблице Key Collector’а находится более 50 столбцов, большая часть которых, обычно, вообще пустует, а потому только мешает. Что делать?
Ответов на этот вопрос может быть несколько.
Пожалуй, самый оптимальный вариант – зайти на вкладку Вид и кликнуть на «Автонастройку видимости колонок». Как видите, пустые колонки просто скрылись.
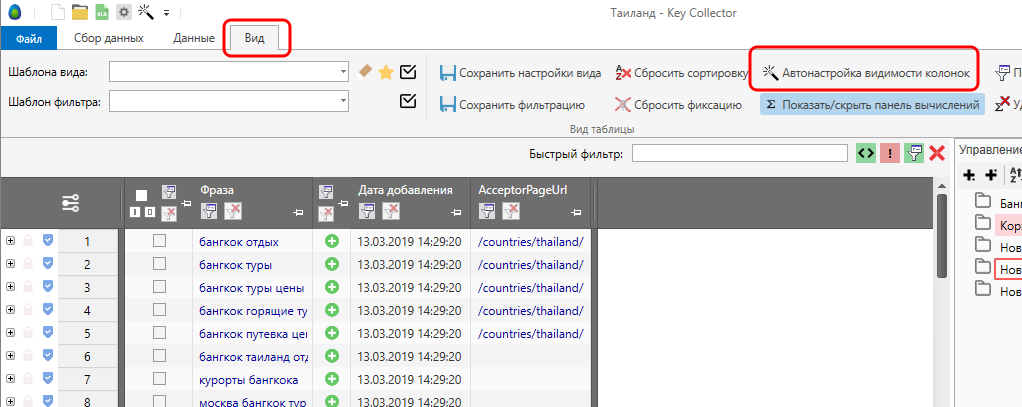
Плюс в том, что Вам больше не будут мешать столбцы с пустыми данными. Минус – столбцы, которые ЗАПОЛНЕНЫ данными тоже иногда могут мешать, т.к. эти данные в данный момент могут быть и вовсе не нужны. Что делать? Правильно – сделать несколько собственных шаблонов «под себя» и при необходимости менять их.
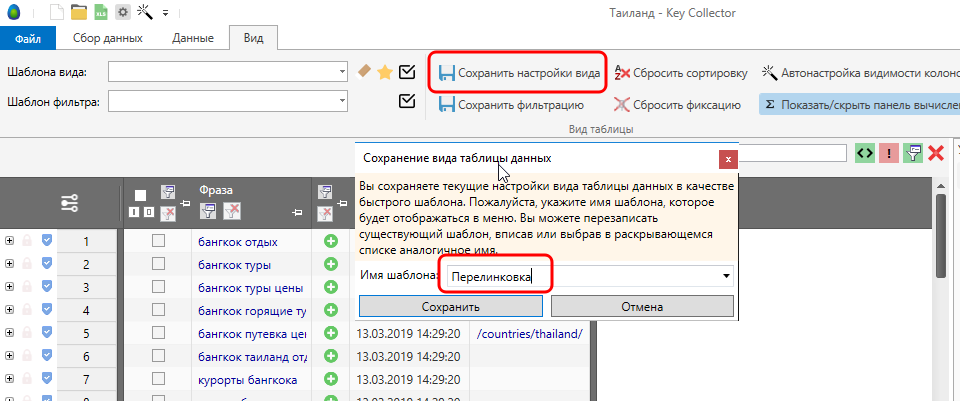
И начнём с сохранения шаблонов. Если взглянуть на скриншот выше, то у нас получился практически готовый шаблон на рекомендации по внутренней перелинковке. Именно так мы его и сохраним.
Теперь давайте его чуточку подправим, удалив столбец с датой добавления и столбец с указанием источника добавления. Для этого кликаем на настройку столбцов, листаем список и убираем лишние галочки.
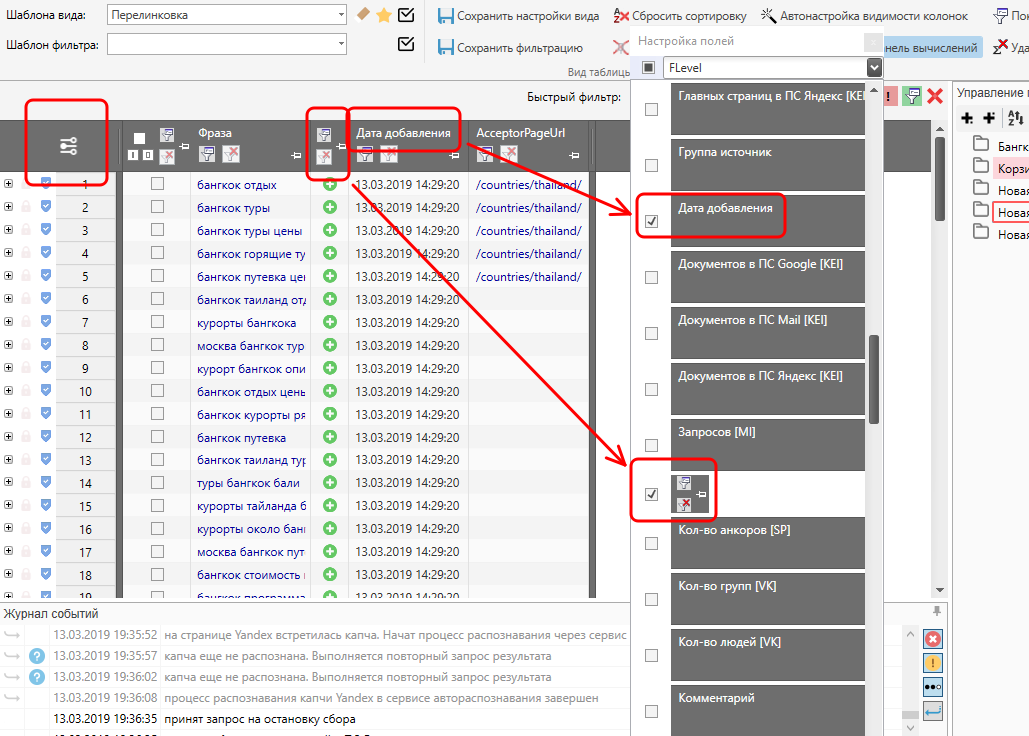
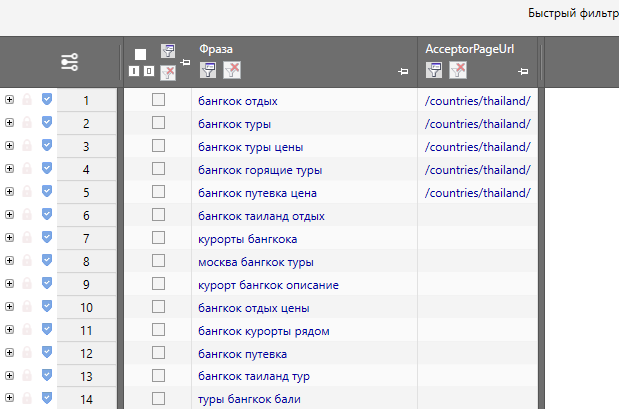
Как видите, таблица снова видоизменилась. Если такой вариант больше устраивает – его вполне можно сохранить как шаблон (причем вместо уже имеющегося).
Теперь давайте сконструируем шаблон, в котором будут отображаться только частоты по Яндексу. Снова заходим в настройки, удаляем столбец с УРЛ и открываем столбцы с частотами.
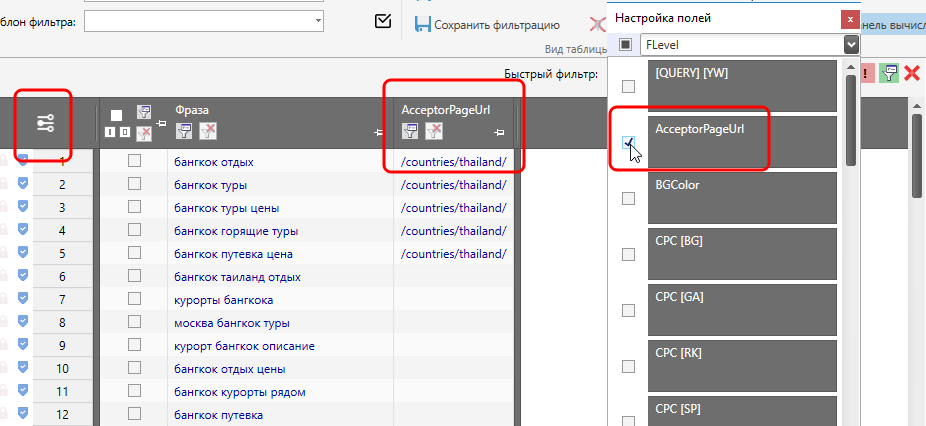
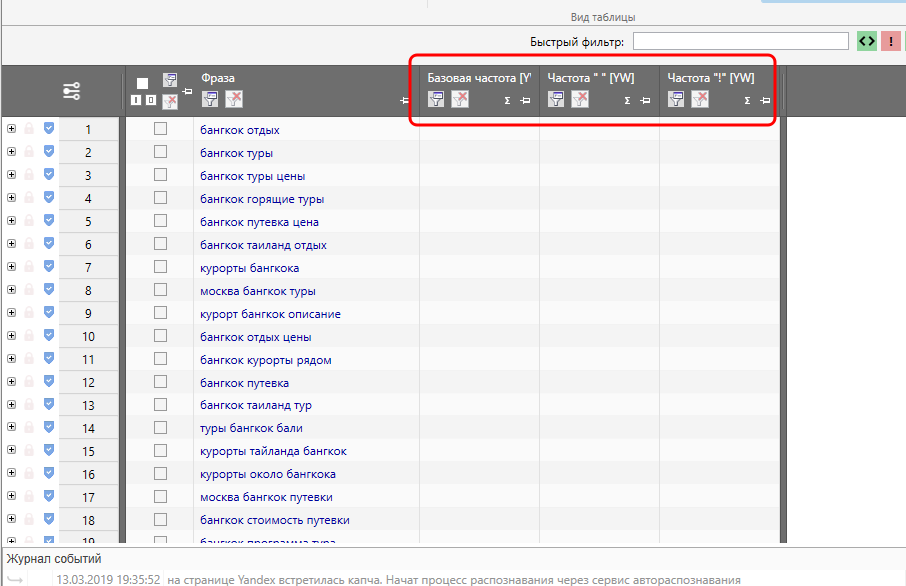
Да, столбцы на данный момент пустые, но это временно и в данном случае неважно. Важно другое. Мы удалили из таблицы столбец с УРЛами, которые получили в качестве рекомендованных акцепторов для перелинковки. И, несмотря на то, что столбец удалён, данные никуда не потерялись. Т.е. если столбец восстановить, то и собранные данные тоже восстановятся.
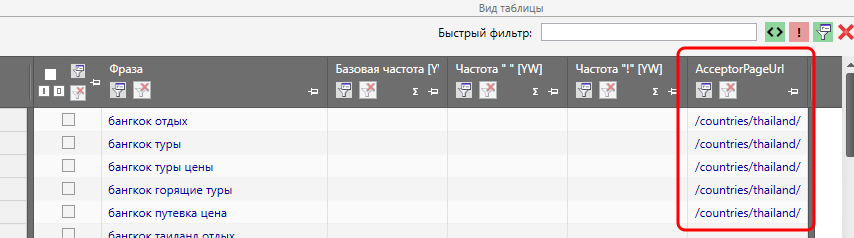
Таким образом, Вы можете сделать «под себя» несколько шаблонов и переключаться между ними по мере необходимости. В крайнем случае у Вас всегда есть возможность настроить отображение ВСЕХ столбцов.
По аналогии можно настроить и шаблоны фильтров. Например, в данном случае настроен фильтр на одновременное соблюдение двух условий – наличие слова «тур» в ключе + наличие ссылки в AcceptorPageURL.
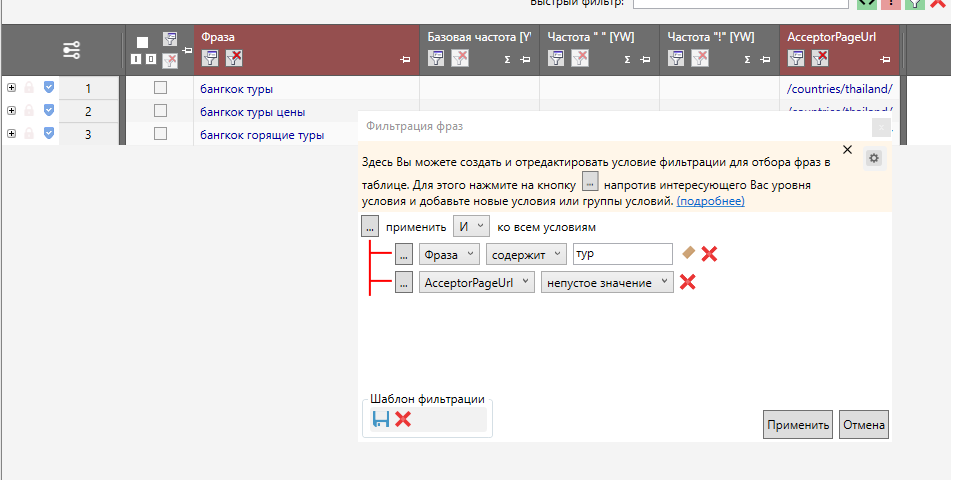
Этот шаблон фильтров тоже можно сохранить:
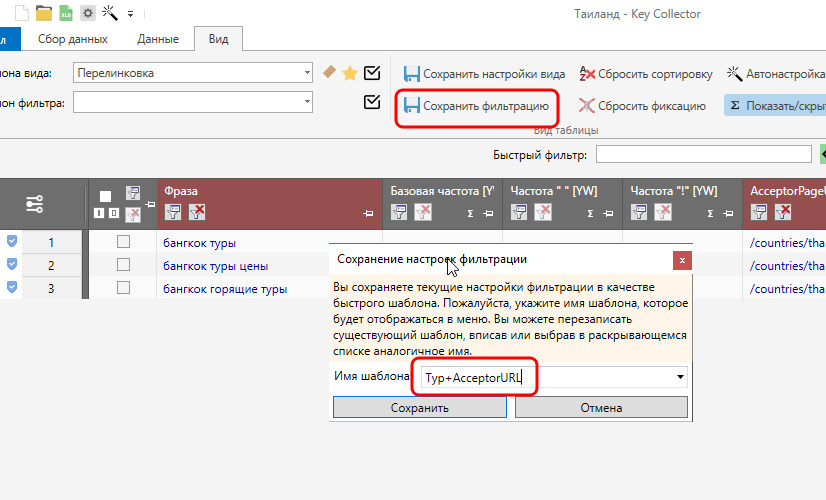
Данная фишка крайне полезна тем, кому периодически приходится задавать однотипные сложные условия, т.е. тоже сводит к минимуму всю возню.
Выводы
Итак, что же мы выяснили?
Мы выяснили, что даже с помощью бесплатных инструментов Вы можете собрать огромное семантическое ядро для дальнейшего продвижения, достаточно быстро очистить его от мусорных запросов, выявить накрученные и «пустые» запросы, выяснить, какие из поисковых запросов являются сезонозависимыми. Разобрались, как спрогнозировать посещаемость сайта и прикинуть уровень конкуренции на основе собранных данных.
Также мы разобрались с интерфейсом, а также с тем, как данный программный комплекс может быть полезен для продвижения YouTube-канала.
А потому можно смело сказать, что программный комплекс Key Collector однозначно мастхэв для каждого SEO-шника, заказчика, YouTube-блогера, а в некоторых случаях – даже для фрилансера.
Ну а самое главное, мы выяснили, что с ТАКИМ функционалом 1800р за пожизненную лицензию –это очень и очень мало – некоторые фрилансеры столько за 1 день зарабатывают.





