СОДЕРЖАНИЕ
ЧПУ (по-Человечески Понятный УРЛы)
Поиск вредоносного кода на сайте
Вот что с сайтом не так? И тексты информативные, которые еще и легко читаются, и картинки есть, и даже куча сопроводительных таблиц и видеороликов присутствует, и дизайн удобный и функциональный, и еще много всяких плюшек… Столько денег потрачено, а позиций нет – как так-то? И вот тут самое время задать встречный вопрос – а Вы уверены, что сайт функционирует как надо? Ведь техническая исправность и работоспособность сайта оказывает прямое влияние на ранжирование сайта в поисковых системах. Вот только есть одна мелочь – мало кто из заказчиков это понимает. Ну а что, это же всего лишь цифры – что им сделается, верно? Нет. По такой логике можно сказать, что «деньги на Вашем банковском счете – это тоже всего лишь цифры». Запомните – между этими двумя видами цифр ВСЕГДА нужно ставить знак равенства. И сайт тоже нужно периодически ремонтировать и обслуживать, как и автомобиль. И проведение технического аудита сайта зачастую и позволяет выяснить, что с сайтом не так, а главное – как это исправить.
В данной статье мы расскажем о том, что вообще включает в себя технический аудит и какие работы по нему должны проводиться, а также частично расскажем Вам о том, как часть этих работ выполнить самостоятельно (например, чтобы немного сэкономить, либо проверить тех, кто проводит аудит Вашего сайта).
Карта сайта Sitemap.xml
1. Карта сайта должна быть в обязательном порядке, ибо без нее индексирование сайта может быть затруднено.
Если коротко и на пальцах, то карта сайта – это просто список с адресами страниц сайта, которые подлежать индексированию. Название файла может быть любым, хоть gcfeskx.xml, ибо в robots.txt в обязательном порядке указывается ссылка на карту.
2. Из карты сайта должны быть исключены страницы, которые не должны индексироваться (например, страница входа в админку сайта, страница регистрации и т.д.). Такие вещи необходимо проверять только вручную (даже при больших объёмах).
3. Адреса страниц в карте сайта должны быть прописаны в том виде, в котором они актуальны. Например, у Вас есть сайт http://vash.site/. Однако, спустя некоторое время Вы перешли с http на https, следовательно, полный адрес сменился. Пусть даже у Вас и настроена автоматическая переадресация, прошлый адрес утратил свою актуальность, а потому все страницы в карте сайта должны быть указаны именно с новым протоколом. То же самое касается и наличия/отсутствия www в адресах. Если поисковый робот попытается посетить страницы, адреса которых не актуальны, то робот за 1 заход проиндексирует меньше страниц, чем мог бы.
4. В карте сайта обязательно должны быть использованы теги urlset, url, loc. Например:
<urlset xmlns="http://www.sitemaps.org/schemas/sitemap/0.9">
<url>
<loc>http://vash.site/</loc>
<lastmod>2005-01-01</lastmod>
<changefreq>monthly</changefreq>
<priority>0.8</priority>
</url>
</urlset>
5. Необходимо убедиться, что размер карты сайта не превышает 10 мегабайт, а количество указанных в ней ссылок не превышает 50000.
На крупных сайтах допускается использование нескольких карт сайта (например, по 1 карте на раздел, если он очень большой), однако в этом случае должна быть карта карт сайта и именно на нее должен ссылаться robots.txt.
В плохом техническом аудите должно быть описано всё, чего не хватает карте сайта и как ее можно улучшить. Хороший же аудит отличается тем, что к нему прилагается готовая карта сайта (или картЫ сайта, если их несколько).
Карту сайта можно сделать и самостоятельно. Например, если у Вас сайт на WordPress, то ее можно сгенерировать огромным количеством специальных плагинов (самый популярный - Yoast SEO). Для Joomla тоже предостаточно плагинов - JL Sitemap, jSitemap, OSMap и т.д.
Ну или альтернативный (и универсальный) вариант - с помощью программы Screaming Frog SEO Spider: указываете домен Вашего сайта, запускаете сканирование, а когда оно будет закончено – заходим в меню Sitemaps, выбираем XML Sitemap и далее следуем инструкциям.
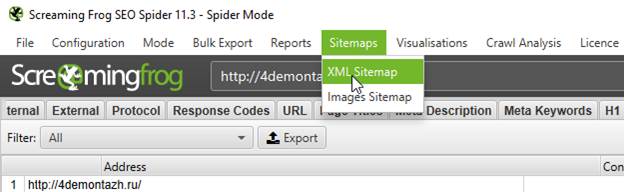
Данная программа хороша тем, что формирует Sitemap.XML с учетом требований файла robots.txt, т.е. если в нём наложен запрет на индексирование ряда страниц, то они в карту сайта добавлены не будут.
Robots.txt

Этот файл необходим для того, чтобы поисковые системы понимали, какие страницы индексировать нужно, а какие – нет. Например, страницу регистрации на сайте индексировать не нужно, т.к. она от сайта к сайту мало чем отличается и никакой пользы для пользователя не несет.
6. Файл ДОЛЖЕН БЫТЬ, причем именно с таким именем и именно в корне сайта, т.е. доступным по ссылке https://vash.site/robots.txt.
7. С помощью директив Disallow необходимо закрыть от индексирования разделы и страницы сайта, которые поисковый робот должен «обойти стороной» (например, страница входа в админку, страница регистрации на сайте и т.д.). Это необходимо для более рационального расходования краулингового бюджета поисковыми роботами (краулинговый бюджет = количество страниц, которое поисковый робот сканирует за одно посещение).
8. Последней строкой должна быть указана ссылка на карту сайта (или на карту карт сайта). Например, вот так:
Sitemap: https://vash.site/sitemap.xml
9. Файлы css и js, а также картинки, скрываться от поисковиков не должны. Если вдруг эти файлы находятся в папке, которая закрыта от индексирования директивой Disallow, то после всех Disallow с помощью директивы Allow должны быть прописаны «исключения» из Disallow-правил.
Например:
Disallow: /service/seo-site-d/
Allow: /service/seo-site-d/*.js
Allow: /service/seo-site-d/*.css
Allow: /service/seo-site-d/*.jpg
Allow: /service/seo-site-d/*.png
Т.е. этими тремя строками мы запрещаем поисковикам индексировать всё содержимое папки /service/seo-site-d/, за исключением js и css файлов. А также картинок в формате png и jpg.
Страница 404 «Не найдено»

Это одна из тех страниц, посещение которой пользователем крайне нежелательно - просто так на нее не попадают, ибо если попадают – значит сайт требуется допилить. В идеале посещений страницы 404 «Не найдено» быть вообще не должно. Тем не менее, этой странице необходимо уделить особое внимание.
10. При посещении страница должна отдавать код ответа 404 Not Found. Это необходимо для того, чтобы поисковый робот понимал, что данную страницу индексировать не нужно. Есть те, кто предпочитает настраивать страницу так, чтобы код ответа был 200, якобы это помогает «смягчить сайту карму», но это давно уже не работает.
11. Сообщение об ошибке (куда же без этого), что запрашиваемая страница не найдена.
12. Обязательно должны быть предложены варианты решения проблема – вернуться на главную, воспользоваться поиском, воспользоваться картой сайта и т.д.
13. Кстати о поиске. Крайне желательно, чтобы поле поиска по сайту присутствовало на странице – это значительно увеличивает вероятность того, что пользователь останется на сайте.
14. Некоторые идут еще дальше и размещают HTML-карту сайта прямо на странице 404. И как ни странно, это работает – пользователи начинают читать заголовки в поисках интересующей их информации. А самое главное – нередко находят ее.
15. Если пользователь вводит несуществующий адрес, то должна производиться переадресация на страницу 404 «Не найдено».
16. Крайне желательно, чтобы адрес страницы 404 «Не найдено» соответствовал ее названию. Например, https://vash.site/404 или https://vash.site/404-not-found, и т.д.
Код сайта и кодировка

Чем легче код сайта – тем ниже нагрузка на сервера хостинга, тем меньше объем передаваемых данных, тем быстрее работает сайт и тем быстрее грузятся страницы. Да, мы не спорим, большая часть кода относится к разряду «без него никак», но никто и не заставляет удалять с сайта весь код «в ноль». Однако, в большинстве случаев удалять часть кода все же приходится.
17. Пустые теги – удалить, незакрытые – закрыть или удалить. Согласитесь, если в коде сайта присутствует код <a class="subcategory-list-item__link dontend" href="" rel="nofollow"></a>, то он будет однозначно лишним, поскольку ссылка никуда не ведёт. Следовательно, его нужно либо исправить (в данном случае – добавить ссылку), либо удалить.
18. Необоснованные комментарии. Нередко в коде сайта бывают комментарии, которые не просто «не обоснованы», а даже написаны на другом языке. Да, комментарии движок игнорирует, но читать их он вынужден как минимум для того, чтобы принять решение об их игнорировании, а это лишняя нагрузка на сервера. И чем меньше необоснованных комментариев будет в коде – тем лучше.
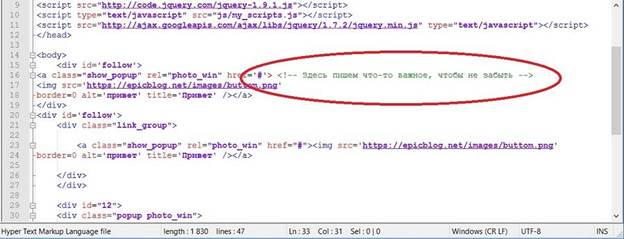
19. Мета-теги generator, base (разумеется, речь идёт о том случае, когда их удаление не влияет на работоспособность сайта). Некоторые идут еще дальше и удаляют даже keywords.
20. Все стили должны быть вынесены в отдельный css-файл.
21. Заголовки H1-H6. Тут все просто – необходимо убедиться, что:
- на всю страницу только один H1-заголовок;
- остальные подзаголовки используются правильно и по иерархии, т.е. нет такого, что после H2 идёт подзаголовок H5;
- заголовок H1 в коде текста находится выше, чем H2-H5-заголовки.
22. Проверить использование noindex, причем речь сейчас:
- о странице в целом, ибо данным тегом можно скрыть от индексирования страницу целиком;
- о внутренней перелинковке, где noindex’а быть вообще не должно.
23. Необходимо, чтобы на каждой странице был прописан тег ее кодировки. Если тега нет – его необходимо добавить – это значительно упростит поисковым системам процедуру распознавания контента.
24. Все файлы сайта должны быть в одной и той же кодировке.
Дубли страниц

Наверняка многим из Вас знакома ситуация, когда одна и та же страница доступна по нескольким адресам. Физически страница одна, но раз адреса разные, то поисковики считают, что и страницы разные. В SEO такие страницы принято называть «техническими дублями», которых на сайте быть не должно. Что же с ним делать?
25. Убедиться, что страница доступна либо только с www., либо без. Т.е. если страница доступна и по адресу https://www.vash.site/ и по адресу https://vash.site/, то это не нормально. Такие дубли необходимо склеить с помощью переадресации с 301 кодом ответа. Например, чтобы с адреса https://www.vash.site/ перебрасывало на https://vash.site/, либо наоборот.
26. Аналогично со слэшем в конце (https://vash.site и по адресу https://vash.site/), тоже «склеиваются с помощью 301 редиректа.
27. Аналогично с http/https, однако, переадресация в этом случае должна быть только с http на https, поскольку он обеспечивает защищенное соединение. «Склейка» тоже проводится с помощью 301 редиректа.
28. index.php, index.html, home.php, home.html, mail.php, main.html и т.д. – если дописать что-то подобное в конец, а содержимое страницы при этом не изменится – это тоже дубль. И снова лечим 301 редиректом.
29. Бывает такое, что к адресу страницы добавляются какие-то параметры. Для поисковой системы это тоже новый адрес = новая страница. Мы называем такие страницы «параметрические дубли». Параметры могут меняться (например, в параметрах может быть прописан другой город, либо другой партнерский код, либо UTM-метка и т.д.) и каждый раз настраивать 301 редиректы, чтобы склеить такие дубли… замучаетесь, однако. Поэтому такие дубли необходимо закрывать от индексирования через директиву Disallow в файле robots.txt.
Бывают и другие ситуации. Например, когда сайт доступен сразу по нескольким доменам. Такие страницы называются «внешними дублями». Откуда они берутся? Например, когда сайт находился в разработке, он был привязан к тестовому домену, а когда сайт перенесли на основной домен – тестовый отвязать забыли. Итог – 2 сайта-клона.
30. Как Вы уже догадались, внешних дублей тоже быть не должно, а если они есть – необходимо настроить редирект с тестового домена на основной.
Есть еще один интересный случай, когда на сайте физически присутствует 2 страницы, которые одинаковы по содержанию. Например, 2 карточки одного и того же товара, находящиеся в разных разделах (или в разных частях одного и того же раздела).
Такие страницы принято называть «физическими дублями». Склеивать их с помощью 301 редиректа бессмысленно – это может вызвать ряд вопросов у пользователя, когда он обнаружит, что оказался не в том разделе, в который заходил.
31. Физические дубли необходимо склеивать с помощью тега rel="canonical", где первая карточка будет ссылаться на саму себя, а вторая – на первую. Таким образом мы дадим поисковому роботу понять, что это одна и та же страница, а заодно и подскажем, какую из этих двух страниц необходимо индексировать.
И сразу же дадим Вам 2 простых способа по поиску дублей.
Способ 1 – сканируем сайт программой Xenu или Screaming Frog SEO Spider, сортируем страницы по Title или H1 и смотрим, есть ли где-нибудь совпадения. Если совпадения есть – заходим на сайт и проверяем страницы вручную.
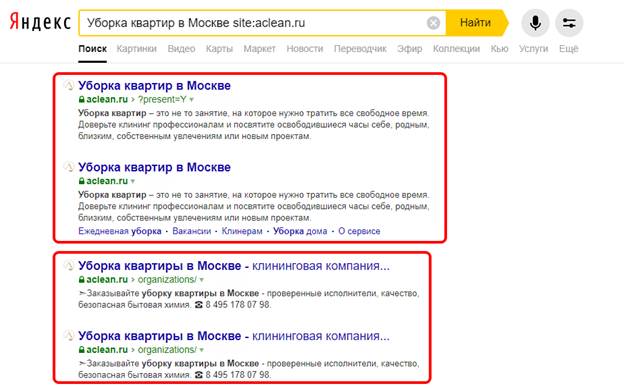
Способ 2 – заходим в Яндекс и Google, в каждую поисковую систему вводим один из основных поисковых запросов, по которым продвигается сайт, добавляем после запроса оператор site:vash.site и смотрим выдачу. Если есть совпадения в пределах ТОП-10 – значит это, скорее всего, дубли. На приведенном ниже скриншоте отчетливо видно, что страницы являются дублями.
ЧПУ (по-Человечески Понятный УРЛы)

Мы прекрасно понимаем, что сами по себе УРЛы уже давно не являются факторами ранжирования сайта. Однако, если посмотреть правде в глаза, понятный УРЛ – это жирный плюс в пользу юзабилити, причем как для пользователей, так и для тех, кто в будущем будет работать с сайтом (например, проводить те же аудиты).
Именно поэтому
32. УРЛ должен быть только таким, чтобы пользователь, прочитав адрес, понимал, где он находится. Т.е. УРЛ должен быть не вот таким:
https://vash.site/?p=545312
а вот таким:
https://vash.site/notebooks/acer/budjet/
33. Допускается использование символов кириллицы. Это может выглядеть странно, но сейчас браузеры отображают такие адреса более чем корректно.

34. УРЛ должен отражать структуру сайта, чтобы пользователю было понятно, какой фрагмент удалить из адреса, чтобы переместиться на 1-2 раздела назад (нередко это бывает проще и быстрее, чем искать эти разделы в меню или в хлебных крошках).
HTTPS

Пару лет назад мы выпустили одну большую статью на тему перехода на https, где рассказали всё от и до – зачем это нужно, какие плюшки даёт и т.д. И знаете, что изменилось с того времени? А изменилось вот что. Поисковые системы и разработчики браузеров делают всё, чтобы сайтов, работающих по http-протоколу было всё меньше. Например, такой сайт может помечаться, как незащищенный.
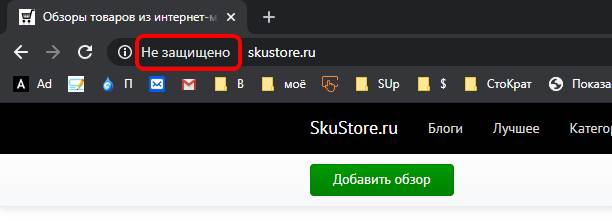
Сейчас всё идет к тому, что браузеры будут вообще блокировать доступ к сайту, если он работает по протоколу http, а не https.
35. Сайт должен работать ТОЛЬКО по https-протоколу.
36. Не должно быть смешанного содержимого (когда текст грузится по https-протоколу, а картинки – по http-протоколу, ну или наоборот, ну или как-то так).
Скорость загрузки страницы

Размер изображений напрямую влияет на скорость загрузки страницы. Чем он больше – тем дольше грузится страница. Именно поэтому
37. Картинки необходимо сжимать, но таким образом, чтобы на глаз разницы не было.
С этой задачей хорошо справляется бесплатный онлайн-сервис https://www.iloveimg.com/ru/compress-image. Хотя сжимать картинки можно по-разному. Например, с помощью все тех же плагинов, которые выпускаются к разным движкам.
38. Обязательно включаем gzip-сжатие (если он не используется) – за счет него сокращается объем передаваемых данных, что тоже влияет на скорость загрузки страницы.
39. Время ответа сервера (до получения первого байта). Чем оно меньше – тем лучше. Норма – 200 миллисекунд. Всё, что выше – это много. Сократить время ответа можно разными способами. Например, отложить загрузку шрифтов (т.е. сначала грузится текст страницы, а потом подгружаются шрифты), изменить тарифный план или даже хостинг-провайдера и т.д.
Про оптимизацию кода повторно говорить не будем, т.к. этой теме посвящен целый раздел данной статьи.
40. Обязательно должен использоваться кэш браузера, тогда часть данных будет подгружаться уже не с сайта, а из кэша – снова сокращение объема передаваемых данных и, как следствие, ускорение загрузки сайта.
41. Стресс-тест сайта, т.е. одновременное открытие большого количества вкладок (хотя бы штук 50). Если хотя бы одна из них отдаст код 500- й серии, то дело плохо, ибо сайт ведет себя не стабильно и есть смысл задуматься о переходе на более дорогой тариф или смене хостинг-провайдера.
Поиск вредоносного кода на сайте

А вот этого не делает практически никто.
42. Неужели сложно просканировать сайт несколькими бесплатными онлайн-антивирусами?
Вот Вам сразу 2 онлайн-антивируса:
Заряжаете туда УРЛ Вашего сайта, сканируете, убеждаетесь, что вредоносный код отсутствует, и радуетесь жизни!
Итоги.
Разумеется, мы многого не рассказали. Например, многие агентства считают, что в аудит необходимо добавлять еще множество другой информации – дубли мета-тегов, мобильную вёрстку, хлебные крошки и т.д. Мы же считаем, что это уже территория SEO- и юзабилити-аудитов, но никак не технического.
В рамках же технического аудита перечисленные 42 пункта – это самый минимум. Если отсутствует хотя бы один пункт – это уже не технический аудит. И не забывайте, что технический аудит проводится с целью диагностики именно ТЕХНИЧЕСКОГО состояния сайта. Тут как с автомобилем: диагностика кузова – это одно, а диагностика двигателя – это совсем другое, причем одно никак не связано с другим.
Ну а про остальные аудиты мы поговорим в следующих статьях.





