СОДЕРЖАНИЕ
Поиск дублей (как страниц, так и мета-тегов)
Поиск страниц с совпадающими Title и H1
Поиск внешних (исходящих) ссылок
Как Вы знаете, мы периодически публикуем обзоры на инструменты, которыми сами пользуемся (ярчайшие примеры – KeyCollector и KeyAssort). Пришло время рассказать про еще один такой мощнейший инструмент. Инструмент называется Screaming Frog Seo Spider. Данную программу можно использовать и бесплатно, но функционал в этом случае будет прилично так урезан.
Обзор на данную программу будет неполным, ибо мы расскажем только про тот функционал, который сами используем. Причем в основном мы используем данную программу при проведении аудитов. Также в этом обзоре нередко будет фигурировать Excel, т.к. именно там мы с помощью формул обрабатываем большие объемы данных буквально в 2 клика.
Запуск сканирования сайта
Ну тут нам ничего не остается, кроме, как просто включить «Капитана Очевидность» и сказать, что перед тем, как приступить к анализу каких-либо данных, эти данные необходимо сначала получить. Этим и займемся.
Первым делом заходим в меню Mode и ставим галочку Spider.
Далее указываем имя сайта и нажимаем Start.
Кстати, с недавних пор это наш клиент (мы про сайт). Разумеется, «весь аудит» мы не покажем, но большинство «основных моментов» все же рассмотрим.
Всё – осталось только дождаться, когда программа завершит сканирование сайта. Имейте в виду, что в бесплатном режиме можно просканировать не более 500 адресов. Хотя… Если сайт очень маленький, то вполне возможно, что в лимит Вы упрётесь нескоро.
Как только сканирование будет окончено, в правом нижнем углу программы появится 100% и точное количество отсканированных адресов.
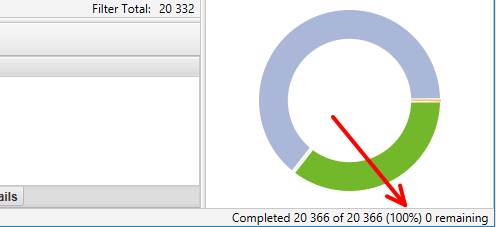
В данном случае их 20366, а это далеко за пределами «бесплатного» лимита. Итак, сканирование завершено. Ну а теперь переходим непосредственно к тому, какие данные мы обычно используем, как их анализируем и какие выводы из этого делаем.
Поиск дублей (как страниц, так и мета-тегов)
В контексте SEO «дублями» принято считать документы, которые доступны по разным адресам. Например, когда одна и та же карточка товара находится в двух разных разделах интернет-магазина и, как следствие, имеет 2 разных адреса.
Однако, в рамках данной статьи речь пойдет не только о дублях документов, но и о дублях мета-тегов. Поэтому давайте договоримся, что дубли страниц мы будем называть «документальными дублями», а дубли мета-тегов – просто «дублями».
По идее было бы логичнее рассказать отдельно про дубли и отдельно про документальные дубли. Но фишка в том, что методика их выявления абсолютно идентична. Более того, с помощью Screamшng Frog Seo Spider имеет смысл имеет смысл искать и то и другое, причем одновременно, чтобы сэкономить на этом кучу времени.
Итак, что мы знаем о документальных дублях? Правильно – у них всегда совпадают мета-теги. Следовательно, выбираем вкладку Page Titles и сортируем заголовки по алфавиту.
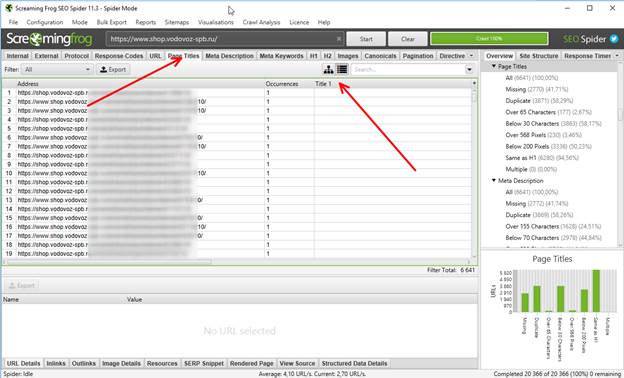
И вот тут мы видим сразу 2 косяка.
Во-первых, на сайте присутствуют страницы как с www., так и без. Следовательно, дубли на сайте присутствуют. Непорядок. Надо заносить эту информацию в аудит и ставить ТЗ на исправление.
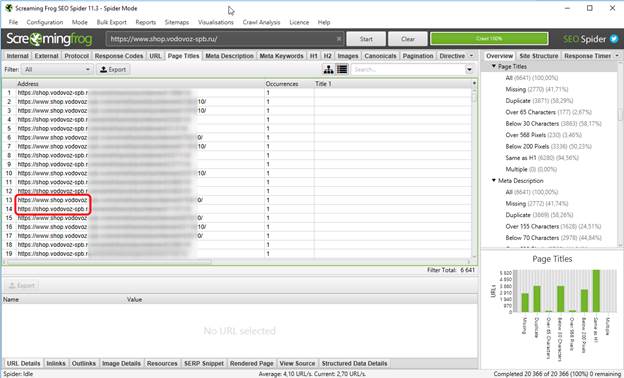
Во-вторых, были обнаружены страницы, на которых Title и вовсе отсутствует. Однако, разобравшись, что это за страницы, вопросы отпали – это технические адреса, при посещении которых:
- товар добавляется в корзину;
- пользователь попадает в корзину, куда товар уже добавлен.
Следовательно, отсутствие заголовка Title в данном случае вполне допускается. Однако, все равно непонятно, имеются ли какие-либо косяки по Title или нет.
Что же делать? Правильно – экспортировать данные в Excel (кстати, в бесплатном режиме эта функция недоступна), для чего нажимаем на Export, даём имя файлу и выбираем желаемый для сохранения формат – текстовый (csv), либо Excel’евский, причем как старый, так и новый. Мы предпочитаем последний.
Вот так выглядит выгруженная из Screaming Frog Seo Spider таблица:
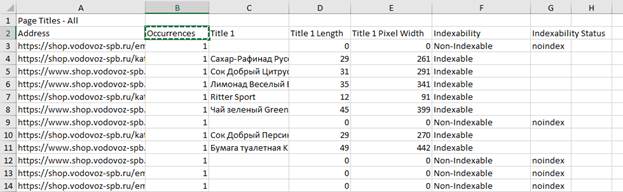
Что же мы видим по таблице?
1) часть страниц не индексируется, о чем свидетельствуют записи “Non-Indexable” и “noindex”, следовательно, эти страницы нужно убрать из таблицы, чтобы они не мешали дальнейшему анализу;
2) не индексируются именно те страницы, которые лишены заголовков Title;
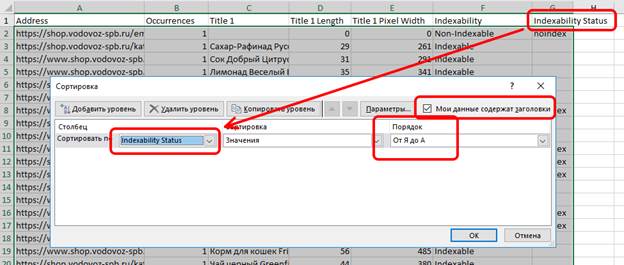
3) на многих страницах очень короткий Title (см 4 и 5 столбцы, где указана длина Title в символах и в пикселях соответственно).
Итак, чистим таблицу от мусора:
1) удаляем первую строку, чтобы Excel не воспринимал ее содержимое, как заголовок таблицы;
2) выделяем таблицу и сортируем по последнему столбцу «от Я до А» - это нужно для того, чтобы все неиндексируемые страницы были в самом верху таблицы;
3) выделяем все строки с неиндексируемыми страницами и удаляем их – их анализировать бессмысленно;
4) повторяем пункт 2), но на этот раз сортируем не по последнему столбцу, а по первому – это необходимо для того, чтобы все адреса с www. были вверху таблицы, затем также выделяем эти строки и удаляем их – ранее мы про эти дубли уже занесли информацию в аудит, а потому на данном этапе все www.-страницы нам будут сейчас только мешать;
5) снова сортируем таблицу, но уже по столбцу Title – это необходимо для того, чтобы адреса с одинаковыми Title были рядом друг с другом.
Упс… А странички с одинаковыми Title-то присутствуют!

Остается только выяснить, являются ли эти дубли документальными. Единственный способ проверить – вручную зайти на каждый из двух адресов, и…
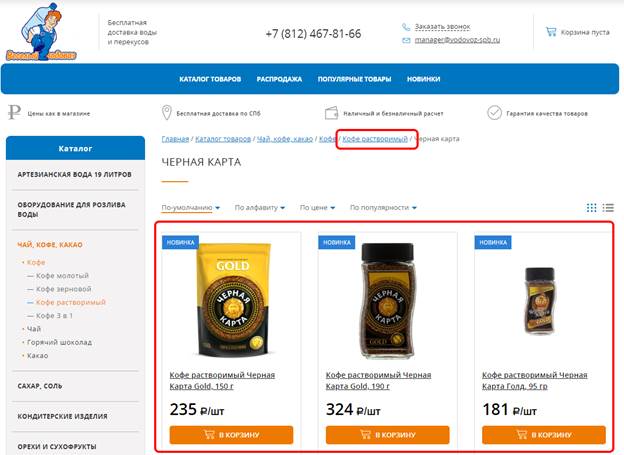
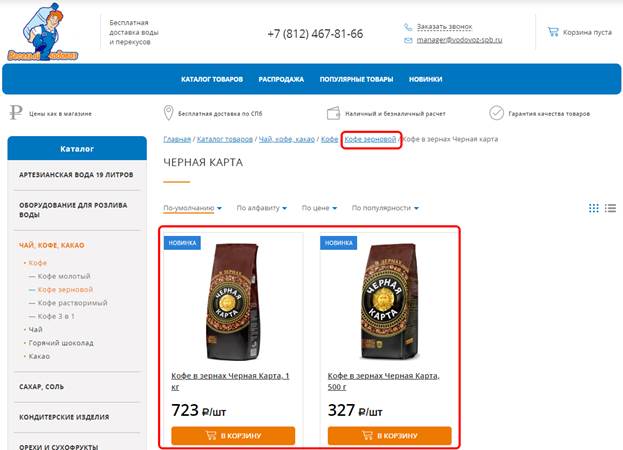
… и, как видим, контент на них отличается. Следовательно, это не документальные дубли.
И вот сейчас многие зададут вопрос – а что делать, если в таблице несколько тысяч адресов, больше половины из которых с совпадающими Title’ами? Как их быстро «выстроить»? Очень просто – с помощью Excel’евской формулы «если».

Что делает данная формула? Допустим, у нас в ячейке C2 присутствует Title. Формула сверяет значение этой ячейки с ячейками на позицию выше и на позицию ниже (т.е. C1 и C3 соответственно). Если совпадение есть – формула так и скажет, мол, СОВПАДЕНИЕ!!! А если нет – промолчит. Теперь осталось «растянуть» эту формулу до конца таблицы.

Ну а теперь сортируем таблицу по значениям последнего столбца от Я до А, тогда все адреса с одинаковыми Title’ами окажутся сверху. Упс… А совпадений-то много, однако!

А это значит, что проверка на то, какие из этих страниц являются документальными дублями, займет некоторое время. Однако, в реальной жизни получение этого списка – дело 1-2 минут после окончания сканирования сайта. Ничего себе?
Спойлер: в данном случае документальных дублей не было (если не считать страницы с www. в начале адреса).
Вот такими нехитрыми манипуляциями мы буквально за пару минут выяснили, что:
- на сайте присутствуют документальные дубли (с www. и без);
- на сайте присутствуют документы с одинаковыми Title;
- на сайте присутствуют документы без Title, но при этом они скрыты от индексирования;
- на сайте присутствуют документы со слишком короткими Title.
Про последний пункт в статье ничего не говорилось, да и говорить особо нечего: если Title слишком длинный, то можно попробовать его сократить (если, конечно, есть возможность), а если слишком короткий, то его можно расширить дополнительными ключевыми словами.
Поиск страниц с совпадающими Title и H1
Как Вы уже знаете из прошлых статей, совпадение мета-тега Title и заголовка H1 в SEO не допускается. Однако, данное явление не является редкостью. Иногда это сделано потому, что заказчик «я сказал делаем так – значит делаем так», но нередко это бывает из-за технических ошибок. В любом случае это не нормально. И снова с помощью Screaming Frog SEO Spider эти страницы (после сканирования) можно найти всем скопом в пару кликов, а именно:
- открываем вкладку “Internal”;
- в списке “Filter” ставим “HTML” – это необходимо для того, чтобы в списке УРЛов были только адреса страниц.
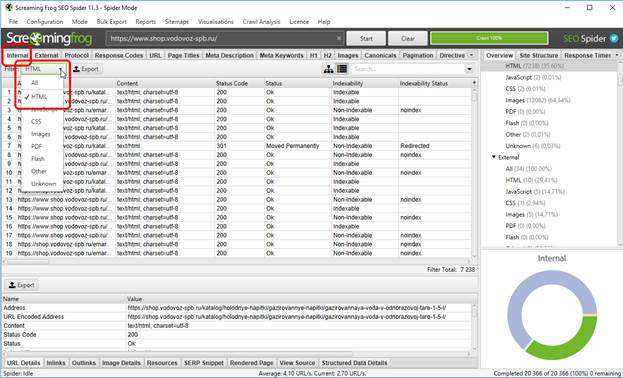
Далее экспортируем данные в эксель, открываем и удаляем из таблицы все столбцы, кроме:
- Address;
- Title 1;
- H1-1;
- H1-2 (если есть);
- Indexability.
Остальные столбцы нам на данном этапе не нужны. Момент с удалением www.-дублей тоже пропустим, впрочем, как и момент удаления неиндексируемых страниц.
Далее сортируем «от Я до А» по столбцу H1-2 – это необходимо для того, чтобы быстро выявить страницы, на которых более одного заголовка H1. Кстати, рекомендуется их отделить от остальных страниц пустой строкой.
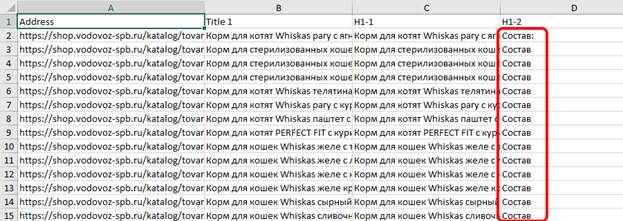
Далее в последнем столбце с помощью оператора =если формируем формулу, которая нам сообщит, в каких именно строках Title совпадает с H1:
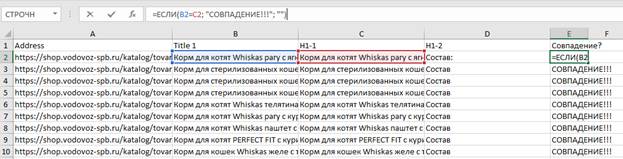
В пределах скриншота совпадения, увы, есть везде. Но ТОЛЬКО в пределах скриншота. Последний штрих – сортируем «от Я до А» по последнему столбцу, чтобы переместить в самый верх таблицы строки, в которых совпадают Title и H1. В реальной жизни эта процедура занимает буквально 2-3 минуты, не более.
По последнему скриншоту видно, что:
- на сайте присутствуют страницы, у которых Title и H1 идентичны;
- у которых более одного H1;
- в большинстве случаев страницы из предыдущих двух пунктов – это одни и те же страницы.
Как видите, с точки зрения SEO на сайте всё очень плохо. А ведь нам это всё придется исправлять…
По дублям закончили.
Как сгенерировать Sitemap.xml
Sitemap.xml на нашем сайте уже давно разжеван вдоль и поперек, поэтому мы не будем снова рассказывать о том, насколько он важен, чем полезен и т.д. Но что делать, если его нет, а настроить его автоматическое генерирование средствами сайта не получается? Правильно – придется генерировать вручную. Но имейте в виду, что необходимо, чтобы robots.txt уже присутствовал на сайте и был составлен правильно – это необходимо для того, чтобы «ненужные» страницы не попали в sitemap.xml. К делу.
Итак, сайт уже просканирован, потому заходим в меню Sitemaps и выбираем XML Sitemap.
В открывшемся окне… короче, можно оставить все настройки по умолчанию и вообще ничего не трогать. Ну… Самый максимум – можно еще поставить галочку “Canonicalised”, что в большинстве случаев это бессмысленно, либо поставить галочку “PDFs” (например, если у Вас прайс-лист оформлен именно в этом формате).
Теперь дело за малым – нажать на кнопку Next, сохранить сгенерированный Sitemap.xml, закинуть его на сайт и (при необходимости) скорректировать на него ссылку в robots.txt. И, вроде бы, всё здорово, но есть еще один важнейший момент… В случае с нашим клиентом такой подход будет… НЕПРАВИЛЬНЫМ, поскольку присутствует большое количество www.-дублей и все они пойдут в sitemap.xml, а это не есть хорошо. В данном случае необходимо:
- склеить www.-дубли с помощью 301-переадресации;
- заново просканировать сайт;
- только потом генерировать sitemap.xml.
Именно в такой последовательности.
С картой сайта, будем считать, разобрались.
Поиск внешних (исходящих) ссылок
Про внешние ссылки уже тоже было многократно рассказано, поэтому сейчас не будем опять заострять внимание на то, когда внешние ссылки можно «оставлять открытыми», а когда нужно закрывать.
Собственно, внешние ссылки после сканирования сайта даже выискивать не нужно – Screaming Frog SEO Spider выносит их на отдельную вкладку – “External”.
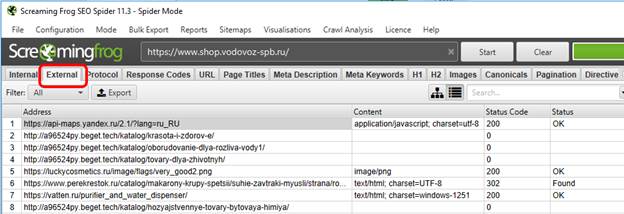
И вот тут, казалось бы, все просто – экспортируем список внешних ссылок, добавляем их в аудит и всё! Но возникает вполне логичный вопрос – ОК, список внешних ссылок мы нашли, но как их искать в пределах сайта? Как узнать, на какой странице располагается вот эта конкретная внешняя ссылка? Очень просто – в самом низу будет вкладка “inlinks”, в которой будет отражена данная информация:
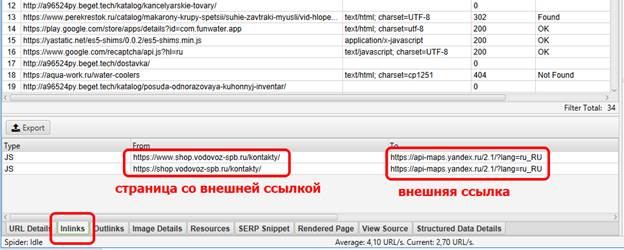
В данном случае у нас чуть более 30 внешних ссылок. Вручную заносить в аудит информацию о том, где каждая из них располагается – это тот еще садизм, поэтому мы поступаем по-хитрому, а именно:
1) выделяем все внешние ссылки, указанные в программе;
2) целиком выделяем столбцы “From” и “To”;
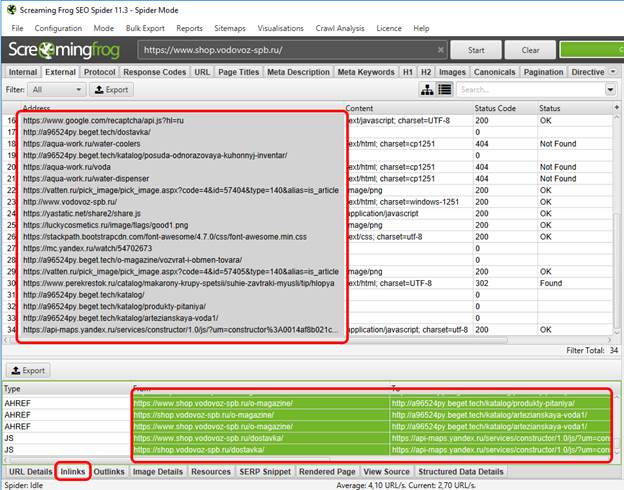
3) копипастим эти 2 столбца в эксель;
4) чистим строки от дублей (на всякий случай).
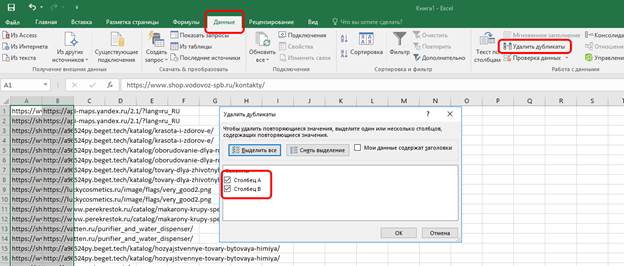
Полученные результаты сохраняем в отдельный эксель-файл и ссылаемся на него в аудите. В данном случае количество строк превысило 36000. Такое бешеное количество строк связано с тем, что большинство внешних ссылок (если не все) являются «сквозными», т.е. находятся на каждой странице сайта (например, в подвале, шапке и т.д.). Следовательно, если убрать одну такую «сквозную» ссылку – таблица резко похудеет на несколько тысяч строк. Не отрицаем, данный подход, мягко говоря, не слишком удобен, но зато так куда сложнее что-то упустить.
Поиск битых ссылок
Про битые ссылки тоже уже не раз рассказывалось на нашем сайте, поэтому останавливаться на теоретической части и рассказывать в очередной раз о том, что битые ссылки необходимо либо исправлять/удалять/переадресовывать [нужное подчеркнуть] не будем и перейдем к практике.
Первым делом переходим на вкладку “Response Codes” (это необязательно, просто вкладка “External” гораздо сильнее нагружена информацией, которая для поиска битых ссылок один фиг не используется). Далее в поиске ставим галочку Status code и в поле поиска вводим всеми нами любимое число 404.
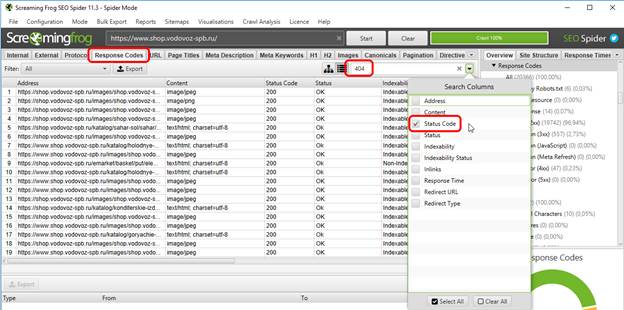
После этого у нас в таблице остаются только битые ссылки, причем как внешние (исходящие), так и внутренние. Как выискивать их расположение на сайте? Ровно так же, как и внешние:
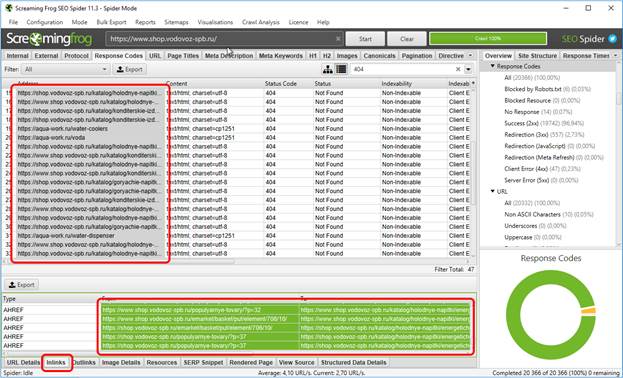
И теперь ровно по той же схеме удаляем повторяющиеся строки и www.-дубли через эксель. Всё – профит!
Хотя, ради справедливости, отметим, что после столбцов “From” и “To” есть и другие. Например, столбец, в котором будет показан текст анкора (если ссылка анкорная), текст тега alt (всплывающая подсказка при наведении) и даже информация о том, является ли это ссылка dofollow (true), либо nofollow (false).
Однако, информацию из этих трех столбцов мы в аудит уже не добавляем – нет необходимости.
Итоги
Вот такой вот получился обзор на «лягушку-скримера». По секрету скажем, что здесь перечислено далеко не всё, что было добавлено в аудит и далеко не всё, что было экспортировано для добавления в тот же аудит. Тем не менее, даже при таком раскладе Вы убедились, что программа крайне полезная в плане диагностики сайта.
Еще раз – что мы сделали:
- выявили битые ссылки, а также страницы, на которых это битьё размещено;
- выявили внешние ссылки;
- выявили документальные дубли;
- выявили дубли мета-тегов, причем как в плане документ1=документ2, так и в плане Title=H1;
- выявили страницы, на которых более одного заголовка H1;
- сгенерировали валидный sitemap.xml (хотя, в данном случае это была ошибка, т.к. присутствуют www.-дубли, но не суть).
Теперь осталось решить самый важный вопрос – а стоит ли платить за эту программу? А вот теперь давайте по-честному.
Если у Вас очень небольшой сайт, то Вам лимита в 500 УРЛ и урезанного функционала на первое время хватит, ибо его достаточно, чтобы выявить «общие» проблемы сайта.
Если же Вы используете Screaming Frog SEO Spider в коммерческих целях (например, для проведения аудита клиентского сайта), то тут имеет смысл поддержать разработчиков финансово. Да, лицензия стоит немало – 149 фунтов, что в пересчете на рубли – примерно 13-13,5 тысяч, причем это цена за год, а не за лайфтайм. Но подумайте вот о чем: 13500 в год = чуть более, чем 1100 рублей в месяц, а теперь вспомните, сколько стоит аудит – минимум в 7-8 раз дороже, а то и в 10, а то и в 15, а сколько таких аудитов Вы делаете в месяц? Ну а если Вы все-таки решили зажать для разработчиков эти 13,5 килорублей, то… Вы знаете, что делать.





