СОДЕРЖАНИЕ
Особенности подбора семантического ядра сайта
Какие ключи использует аудитория
Кластеризация семантического ядра
Как выполняется кластеризация запросов
Программы для создания семантического ядра
Планировщик ключевых слов Google
Как узнать семантическое ядро сайта конкурента
Ошибки при составлении семантического ядра
Самая частая ошибка – очень маленькое семантическое ядро
Вторая ошибка – синонимайзинг. Точнее – его отсутствие
Составление семантического ядра исключительно из ВЧ-запросов
«Мусор», т.е. нецелевые запросы
Отсутствие группировки запросов
Ошибки в разделении коммерческих и информационных запросов
Пример семантического ядра сайта
Если у Вас встал вопрос «Как составить семантическое ядро», то перед решением надо сначала разобраться, с чем Вы связались.
Семантическое ядро сайта представляет собой список фраз, которые вводят пользователи в поисковых системах. Соответственно, продвигаемые страницы должны отвечать на пользовательские запросы. Разумеется, нельзя пихать на одну и ту же страницу кучу разнотипных ключевых фраз. Один основной поисковый запрос = одна страница.
Важно, чтобы ключевые слова соответствовали тематике сайта, не имели грамматических ошибок, имели вменяемую частотность, а также соответствовали по ряду других характеристик.
Семантическое ядро обычно хранится в Excel-таблице. Эту таблицу можно хранить/создать где угодно – на флешке, в Google Docs, на Яндекс.Диске либо где-то еще.
Вот наглядный пример простейшего оформления:
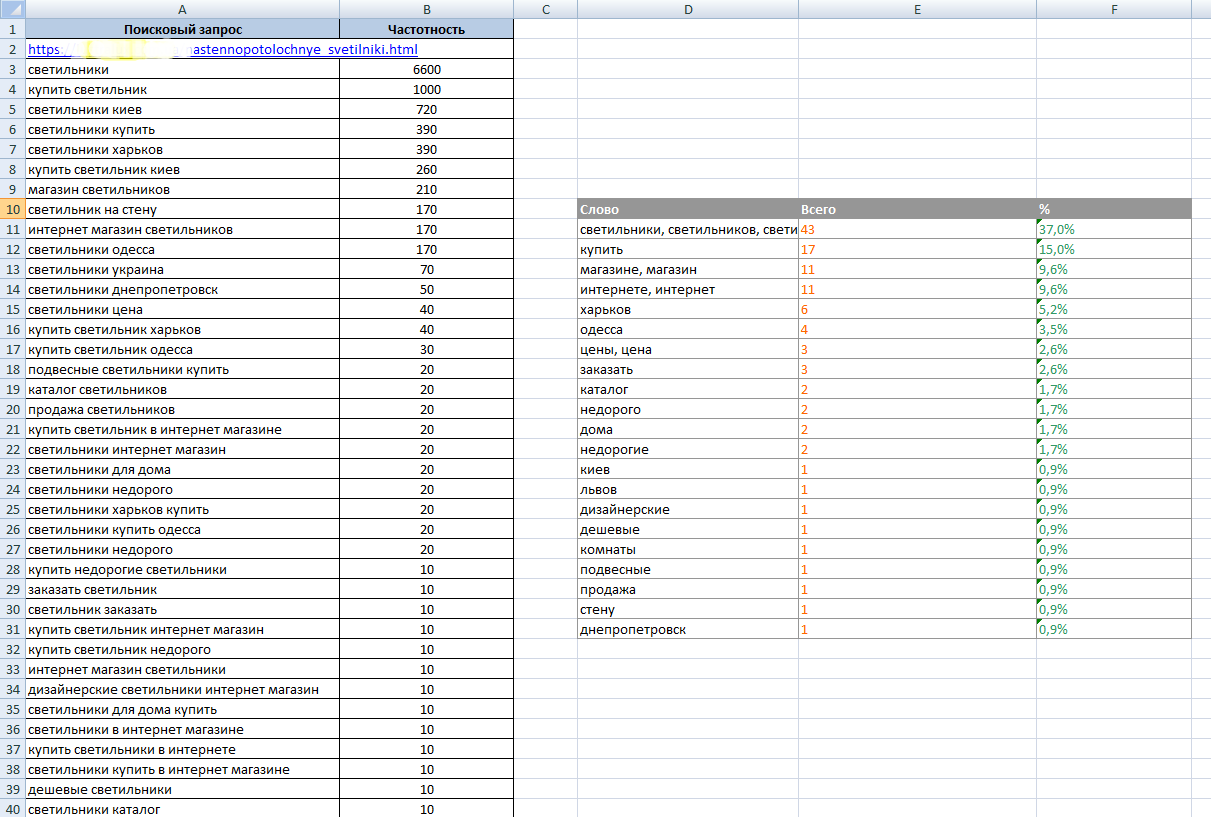
Особенности подбора семантического ядра сайта
Для начала следует понимать (хотя бы примерно) какие именно фразы использует Ваша аудитория при работе с поисковой системой. Этого будет вполне достаточно для работы с инструментами по подбору ключевых фраз.
Какие ключи использует аудитория
Ключи — это как раз и есть те самые фразы, которые пользователи вводят в поисковые системы для получения той или иной информации. Например, если человек хочет купить холодильник, он так и пишет – «купить холодильник», ну или «купить холодильник недорого», «купить холодильник samsung» и т.д., в зависимости от предпочтений.
Теперь давайте разбираться с признаками, по которым можно классифицировать ключи.
Признак 1 – популярность. Здесь ключи можно условно разделить на высокочастотные, среднечастотные и низкочастотные.
Низкочастотные запросы (иногда обозначаются как НЧ) имеют частоту до 100 показов в месяц, среднечастотные (СЧ) – до 1000, а высокочастотные (ВЧ) – от 1000.
Однако, эти цифры являются чисто условными, ибо есть масса исключений из этого правила. Например, тематика криптовалюты. Здесь гораздо правильнее считать низкочастотными запросы с частотой до 10000 показов в месяц, среднечастотными – от 10 до 100 тысяч, а высокочастотными – все остальное. На сегодня ключевое слово «криптовалюта» имеет частоту более 1,5 миллионов показов в месяц, а «биткоин» зашкалил за 3 миллиона.
И несмотря на то, что «криптовалюта» и «биткоин», на первый взгляд, являются очень вкусными поисковыми запросами, гораздо правильнее (как минимум на начальных этапах) делать акцент именно на низкочастотых запросах. Во-первых, потому что это более точные запросы, а значит, приготовить релевантный контент будет проще. Во-вторых, низкочастотных запросов ВСЕГДА в десятки-сотни раз больше, чем высокочастотных и среднечастотных (причем в 99,5% случаев – еще и вместе взятых). В-третьих, «низкочастотное ядро» гораздо проще и быстрее расширить, чем два других. НО… Это не значит, что СЧ и ВЧ нужно игнорировать.
Признак 2 – потребности пользователя. Здесь можно условно разделить на 3 группы:
- транзакционные – подразумевают какое-то действие (содержат в себе слова «купить», «скачать», «заказать», «доставка» и т.д.)
- информационные – просто поиск тех или иных сведений («что будет, если», «что лучше», «как правильно», «как сделать», «описание», «характеристики» и т.д.)
- прочие. Это особая категория, т.к. непонятно, чего именно хочет пользователь. Для примера возьмем запрос «торт». «Торт» что? Купить? Заказать? Испечь по рецепту? Посмотреть фотографии? Непонятно.
Теперь о применении второго признака.
Во-первых, данные запросы лучше не «смешивать». Например, у нас есть 3 поисковых запроса – «ноутбук dell 5565 amd a10 8 гб hd купить», «ноутбук dell 5565 amd a10 8 гб hd обзор» и «ноутбук dell 5565 amd a10 8 гб hd». Ключи почти полностью идентичны. Однако, именно отличия и играют решающую роль. В первом случае мы имеем «транзакционный» запрос, по которому нужно продвигать именно карточку товара. Во втором – «информационный», а в третьем - «прочий». И если по информационному ключу нужна отдельная страница, то логично задать вопрос – а что делать с третьим ключом? Очень просто – просмотреть ТОП-10 Яндекса и Google по данному запросу. Если будет много торговых предложений – значит запрос все-таки коммерческий, а если нет – значит информационный.
Во-вторых, транзакционные запросы можно условно подразделить еще и на «коммерческие» и «некоммерческие». В коммерческих запросах придется конкурировать с «тяжеловесами». Например, по запросу «купить samsung galaxy» придется конкурировать с Евросетью, Связным, по запросу «купить духовой шкаф ariston» - с М.Видео и Эльдорадо. И что делать? Очень просто – «замахиваться» на запросы, у которых гораздо более низкая частота. Например, на сегодня запрос «купить samsung galaxy» имеет частоту около 200 000 показов в месяц, в то время, как «купить samsung galaxy a8» (а это уже вполне конкретная модель линейки) имеет частоту 3600 показов в месяц. Разница в частоте громадная, но по второму запросу (именно за счет того, что подразумевается вполне конкретная модель) можно получить гораздо больше трафика, чем по первому.
Анатомия поисковых запросов
Ключевую фразу можно разбить на 3 части – тело, спецификатор, хвост.
Для наглядности возьмем уже рассмотренный ранее «прочий» запрос – «торт». Чего хочет пользователь – непонятно, т.к. он состоит только из тела и не имеет спецификатора и хвоста. Однако, он высокочастотный, а значит имеет бешеную конкуренцию в поисковой выдаче. Однако, 99,9% при посещении сайта скажет «нет, это не то, что я искал» и просто уйдет, а это негативный поведенческий фактор.
Добавим спецификатор «купить» и получаем транзакционный (а в качестве бонуса – еще и коммерческий) запрос «купить торт». Слово «купить» отражает намеренья пользователя.
Поменяем спецификатор на «фото» и получим запрос «торт фото», который уже не является транзакционным, ибо пользователь просто ищет фотографии тортов и ничего покупать не собирается.
Т.е. именно с помощью спецификатора мы и определяем какой это запрос – транзакционный, информационный или прочий.
С продажей тортов разобрались. Теперь к запросу «купить торт» добавим словосочетание «на свадьбу», которое будет являться «хвостом» запроса. Именно «хвосты» делают запросы более конкретными, более детальными, но при этом не отменяют намерений пользователя. В данном случае – раз торт свадебный, то торты с надписью «с днем рождения» отметаются сразу, т.к. они не подходят по определению.
Т.е. если взять запросы:
- купить торт на рождение ребенка
- купить торт на свадьбу
- купить торт на юбилей
то мы увидим, что цель пользователя одна и та же – «купить торт», а «на рождение ребенка», «на свадьбу» и «на юбилей» отражают потребность более детально.
Теперь, когда Вы знаете анатомию поисковых запросов, можно вывести некую формулу подбора семантического ядра. Для начала определяете некие базовые термины, имеющие прямое отношение к Вашей деятельности, а затем собираете наиболее подходящие спецификаторы и хвосты (расскажем немного позже).
Кластеризация семантического ядра
Под кластеризацией подразумевается распределение собранных ранее запросов по страницам (даже если страницы еще не созданы). Зачастую этот процесс называют «группировкой семантического ядра».
И вот тут многие допускают одну и ту же ошибку – разделять запросы нужно по смыслу, а не по количеству имеющихся страниц на сайте или в разделе. Страницы при необходимости всегда можно создать.
Теперь давайте разберемся, какие ключи куда распределять. Сделаем это на примере структуры, в которой уже есть несколько разделов и групп:
- Главная страница. Для нее отбираются только самые важные, конкурентные и высокочастотные запросы, являющиеся основой продвижения сайта в целом. («салон красоты в Санкт-Петербурге»).
- Категории услуг/товаров. Здесь вполне логично разместить запросы, не содержащие в себе особой конкретики. В случае с «салоном красоты в СПб» вполне логично создать несколько категорий по ключам «услуги визажиста», «мужской зал», «женский зал» и т.п.
- Услуги/товары. Здесь уже должны фигурировать более конкретные запросы – «свадебные прически», «маникюр», «вечерние прически», «окрашивание» и т.п. В какой-то степени это «категории внутри категории».
- Блог. Сюда подойдут информационные запросы. Их гораздо больше, чем транзакционных, поэтому и страниц, которые будут им релевантны, должно быть больше.
- Новости. Сюда выделяются ключи, наиболее подходящие для создания коротких новостных заметок.
Как выполняется кластеризация запросов
Существует 2 основных способа кластеризации – ручная и автоматическая.
У ручной кластеризации есть 2 основных минуса: долго, трудоёмко. Однако, весь процесс контролируется лично Вами, а значит можно добиться очень высокого качества. Для ручной кластеризации будет вполне достаточно Excel’я, Google Таблиц либо Яндекс.Диска. Главное – иметь возможность фильтровать и сортировать данные по тем или иным параметрам.
Многие для кластеризации используют сервис Keyword Assistant. По сути, это ручная кластеризация с элементами автоматики.
Теперь рассмотрим плюсы и минусы автоматической группировки, благо, сервисов много (как бесплатные, так и платные) и выбирать есть из чего.
Например, внимания достоин бесплатный сервис кластеризации от команды SEOintellect. Он подойдет для работы с небольшими семантическими ядрами.
Для «серьезных» объемов (несколько тысяч ключей) уже имеет смысл пользоваться платными сервисами (например, Топвизор, SerpStat и Rush Analytics). Работают они следующим образом: Вы загружаете ключевые запросы, а на выходе получаете готовы Excel-файл. Упомянутые выше 3 сервиса работают примерно по одной и той же схеме – группируют по смыслу, анализируя пересечение фраз, а также по каждому запросу просматривают ТОП-30 поисковой выдачи, чтобы выяснить, на скольких URL встречается запрашиваемая фраза. На основе вышеперечисленного и происходит распределение по группам. Происходит все это «в фоне».
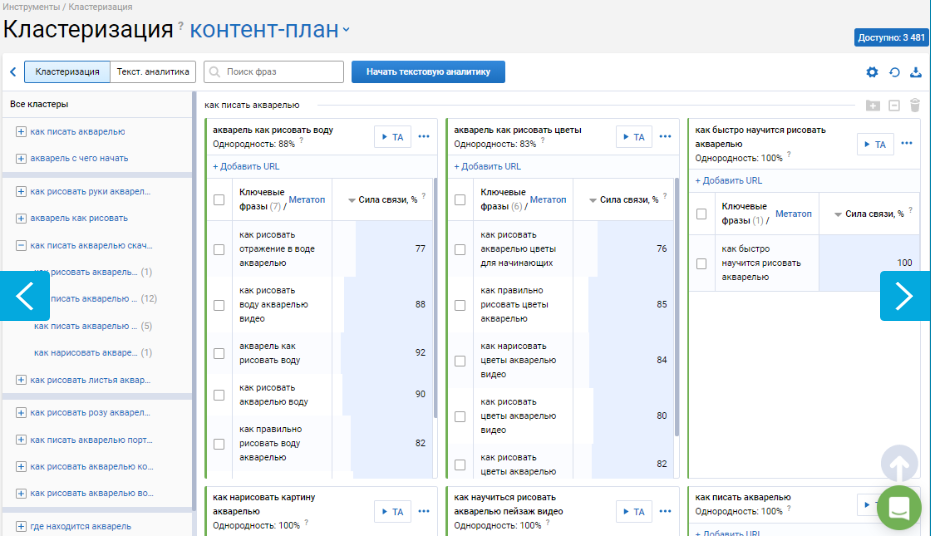
Программы для создания семантического ядра
Для сбора подходящих поисковых запросов есть множество платных и бесплатных инструментов, есть из чего выбрать.
Начнем с бесплатных.
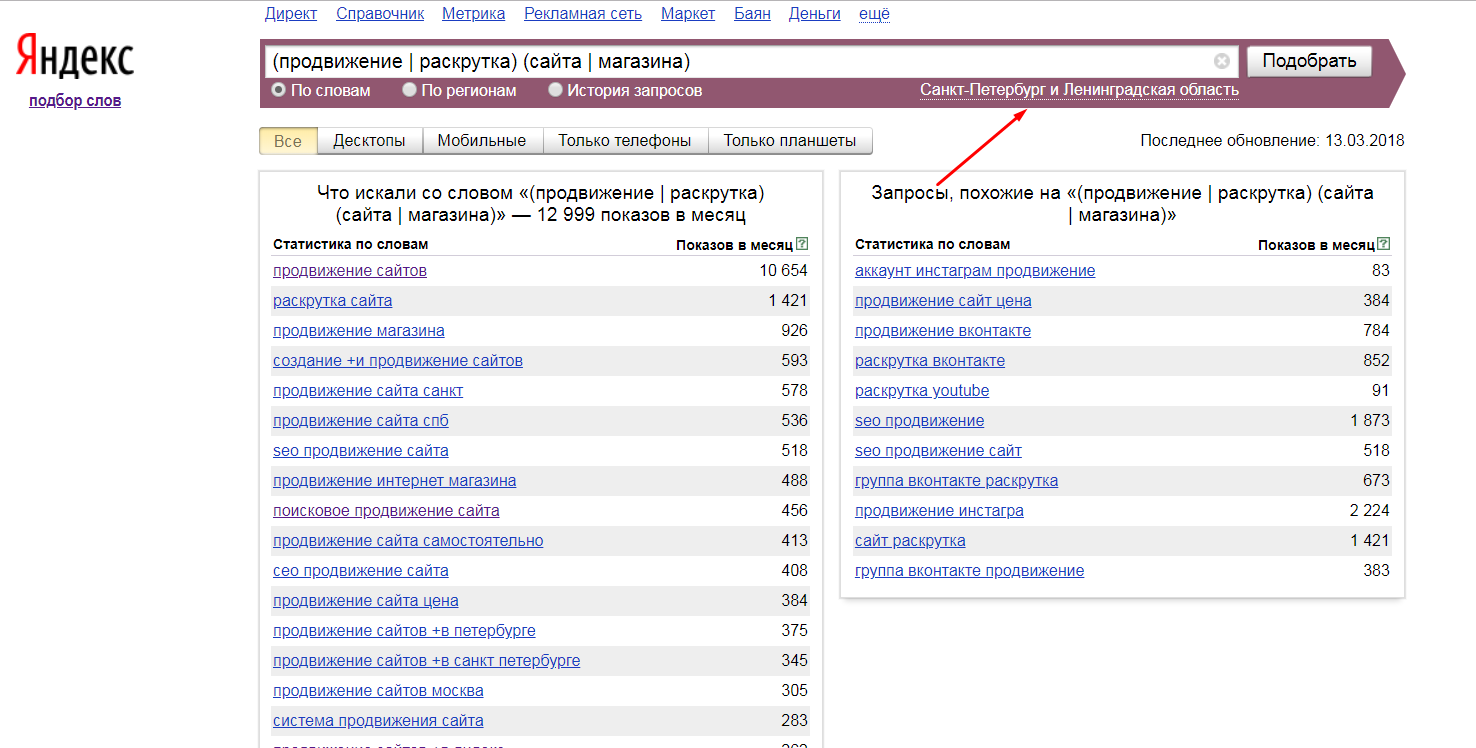
Сервис wordstat.yandex.ru. Это бесплатный сервис. Для удобства рекомендуется установить в Ваш браузер плагин Wordstat Assistant. Именно поэтому мы будем рассматривать эти 2 инструмента в паре.
Как это работает?
Очень просто.
Для примера мы соберем небольшое ядро по путевкам в Анталию. В качестве «базовых» у нас будет 2-й запрос – «туры в анталию» (в данном случае количество «базовых» запросов не принципиально).
Теперь переходим по адресу https://wordstat.yandex.ru/, логинимся, вставляем первый «базовый» запрос и получаем список ключей. Затем с помощью «плюсиков» добавляем подходящие ключи в список. Обратите внимание, если ключевая фраза окрашена в синий и слева обозначена плюсом, значит ее можно добавить в список. Если же фраза «обесцвечена» и помечена минусом – значит она в список уже добавлена, а нажатие на «минус» приведет к ее удалению из списка. Кстати, список ключей слева и плюсы-минусы – это и есть те самые фишки плагина Wordstat Assistant, без которых работа в Яндекс.Wordstat вообще не имеет смысла.

Также стоит отметить, что список будет сохранен ровно до тех пор, пока он лично Вами не будет откорректирован или очищен. Т.е. если вбить в строку «телевизоры samsung», то список ключей Яндекс.Wordstat обновится, но ранее собранные ключи в списке плагина сохранятся.

По этой схеме прогоняем через Wordstat все заранее подготовленные «базовые» ключи, собираем всё необходимое, а затем путем нажатия на одну из этих двух кнопок копируем собранный ранее список в буфер обмена. Обратите внимание, что кнопка с двумя листиками копирует список без частот, а с двумя листиками и числом 42 – с частотами.

Затем скопированный в буфер обмена список можно вставить в таблицу Excel.
Также в процессе сбора можно просмотреть статистику показов по регионам. Для этого в Яндекс.Wordstat есть вот такой переключатель.
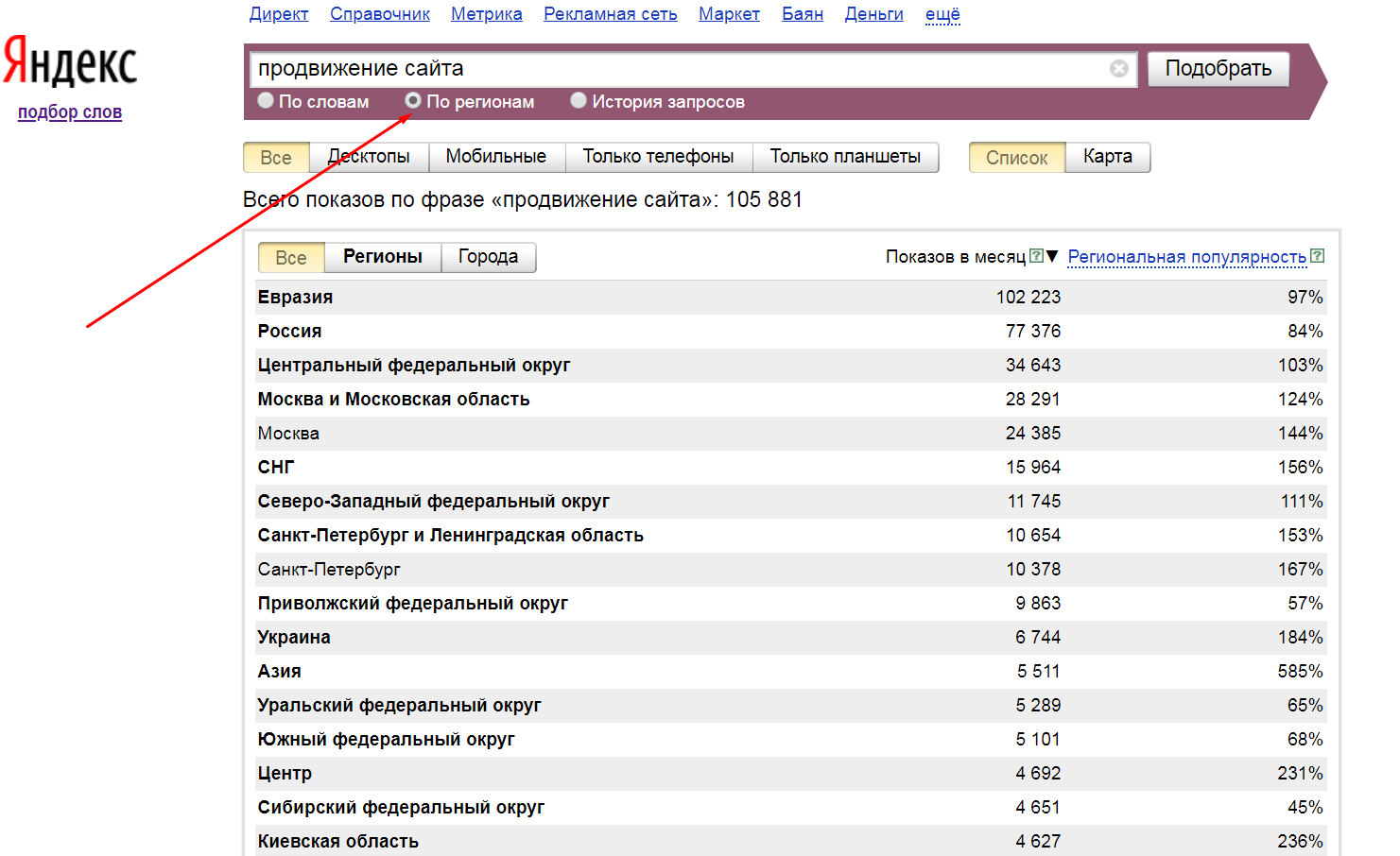
Ну а в качестве бонуса можно глянуть историю запроса – узнать, когда частота повышалась, а когда – понижалась.
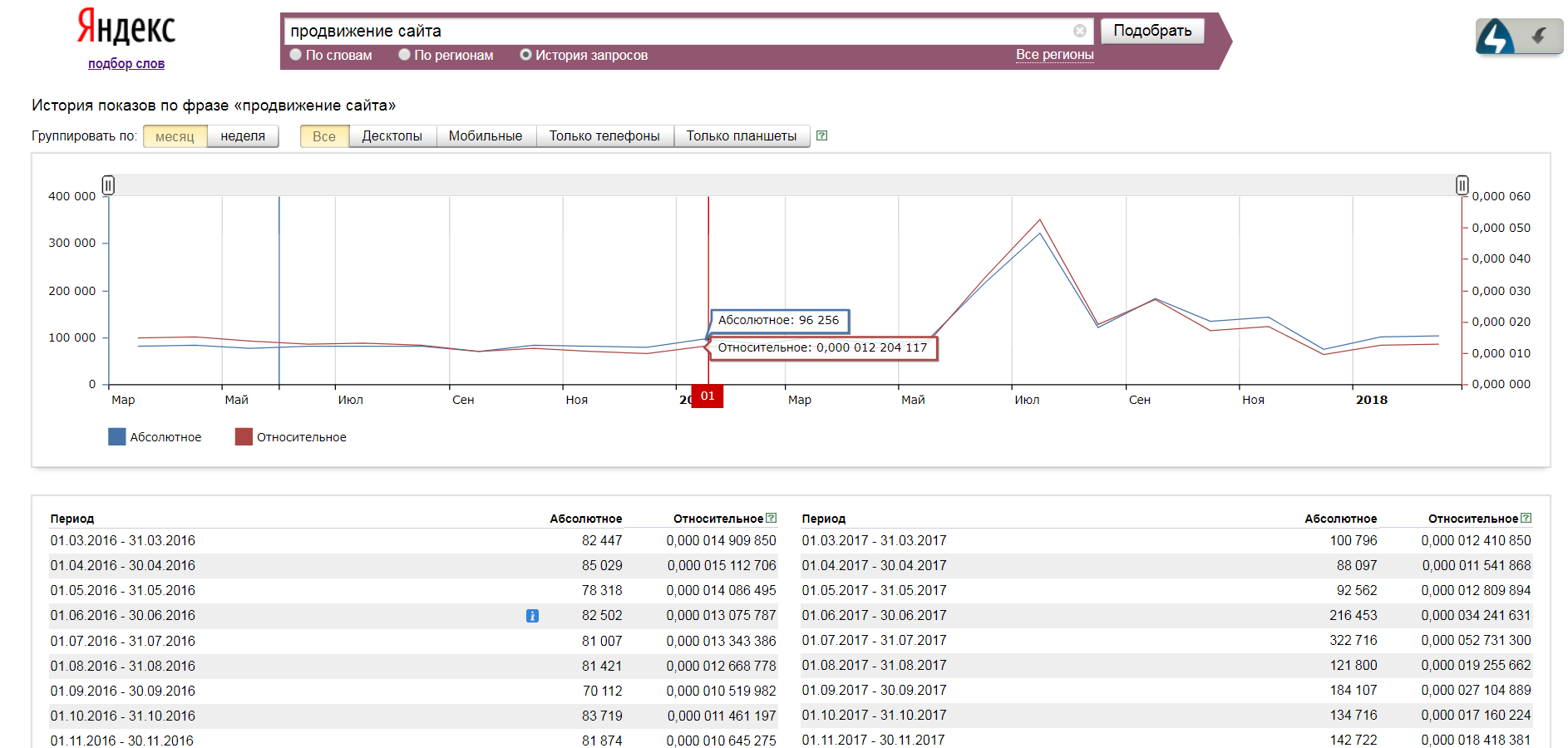
Данная фишка может быть полезна при определении сезонности запроса, а также для выявления падения/роста популярности.
Еще одной интересной фишкой является статистика показов по указанной фразе и ее формам. Для этого необходимо заключить запрос в кавычки.
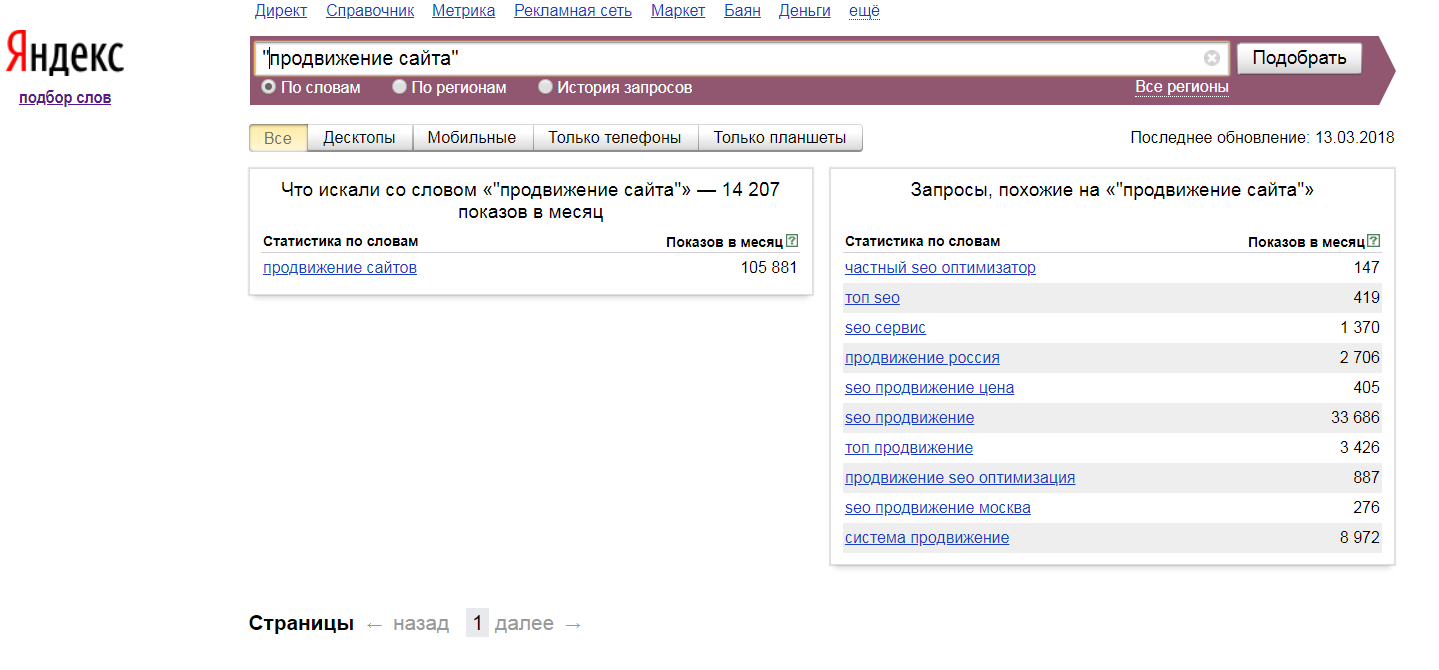
Ну а если перед каждым словом добавить еще и восклицательный знак, то в статистике будет отображено количество показов по ключу без учета словоформ.
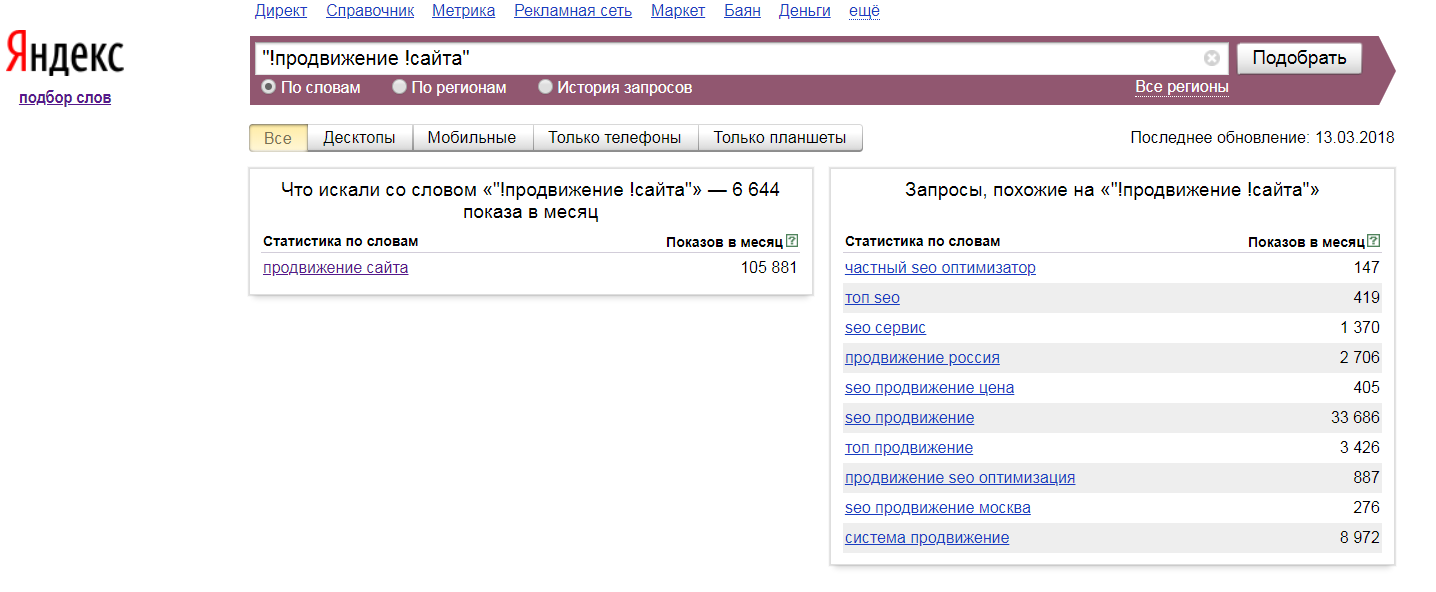
Не менее полезным является оператор «минус». Он убирает ключевые фразы, в которых содержится указанное Вами слово (или несколько слов).

Есть и еще один хитрый оператор – вертикальный разделитель. Он необходим для того, чтобы объединить сразу несколько списков ключей в один (речь про однотипные ключи). Для примера возьмем два ключа: «туры в анталию» и «путевки в анталию». В строке Яндекс.Wordstat прописываем их следующим образом и получаем на выходе 2 списка по этим ключам, объединенных в один:

Как видите, у нас куча ключей, где есть «туры», но нет «путевок» и наоборот.
Еще одной важнейшей фишкой является привязка частоты к региону. Регион можно выбрать вот тут.
Использование Wordstat для сбора семантического ядра подойдет в том случае, если Вы собираете мини-ядра для каких-то отдельных страниц, либо не планируете больших ядер (до 1000 ключей).
SlovoEB и Key Collector
СловоЁБ
Мы не прикалываемся, программа именно так и называется. Если в двух словах, то программа позволяет делать ровно то же самое, но в автоматическом режиме.
Данная программа разработана командой LegatoSoft – та самая команда, которая разработала Key Collector, о нем тоже пойдет речь. По сути, Словоёб является сильно обрезанной (но бесплатной) версией Кей Коллектора, однако для работы со сбором небольших семантических ядер он вполне справляется.
Специально для Словоёба (или Кей Коллектора) имеет смысл создать отдельный аккаунт на Яндексе (если забанят – не жалко).
Единоразово необходимо произвести небольшие настройки.

Пару логин-пароль необходимо прописывать через двоеточие и без пробелов. Т.е. если Ваш логин my_login@yandex.ru и пароль 15101510ioioio, то пара будет выглядеть вот так: my_login:15101510ioioio
Обратите внимание – прописывать в логине @yandex.ru нет необходимости.
Данная настройка является единоразовым мероприятием.
Далее создаем новый проект, даем ему имя и куда-нибудь сохраняем (например, на флешку, в «Мои документы» либо на «Рабочий стол»).

Сразу проясним пару моментов:
- сколько проектов создавать для каждого сайта – решать только Вам
- без создания проекта программа работать не будет.
Теперь давайте разбираться с функционалом.
Для сбора ключей из Яндекс.Wordstat на вкладке «Сбор данных» нажимаем на кнопку «Пакетный сбор слов из левой колонки Яндекс.Wordstat», вставляем список ранее подготовленных ключевых фраз, нажимаем «Начать сбор» и ждем его окончания. Минус у такого способа сбора только один – после окончания парсинга приходится вручную удалять ненужные ключи.

На выходе мы получаем таблицу с собранными из Wordstat ключевыми словами и базовой частотой показов.

Но мы-то с Вами помним, что можно еще задействовать кавычки и восклицательный знак, верно? Этим и займемся. Тем более что данный функционал в Слоёбе реализован.

Запускаем сбор частот в кавычках и наблюдаем за тем, как данные будут постепенно появляться в таблице.

Единственный минус состоит в том, что сбор данных производится через сервис Яндекс.Wordstat, а это значит, что даже на сбор частот по 100 ключам будет уходить достаточно много времени. Однако, эта проблема решена в Key Collector’е.
И еще одна функция, о которой хотелось бы рассказать – сбор поисковых подсказок. Для этого копируем список ранее спарсенных ключей в буфер обмена, нажимаем кнопку сбора поисковых подсказок, вставляем список, выбираем поисковые системы, с которых будет вестись сбор поисковых подсказок, нажимаем «Начать сбор» и ждем его окончания.
На выходе мы получаем расширенный список ключевых фраз.

Теперь переходим к «старшему брату» Словоёба – Key Collector’у.
Key Collector платный, но имеет гораздо более широкий функционал. Так что если Вы профессионально занимаетесь продвижением сайтов или маркетингом – Key Collector просто мастхэв, ибо Словоёба будет уже недостаточно. Если коротко, то Кей Коллектор умеет выполнять:
- Парсить ключи из Wordstat*.
- Парсить поисковые подсказки*.
- Отсечка поисковых фраз по стоп-словам*.
- Сортировка запросов по частоте*.
- Выявление запросов-дублей.
- Определение сезонных запросов.
- Сбор статистики из Liveinternet.ru, «Метрика», Google Analytics, Google AdWords, «Директ», «Вконтакте» и другие.
- Определение релевантных страниц по тому или иному запросу.
(знаком * отмечен функционал, имеющийся в Словоёбе)
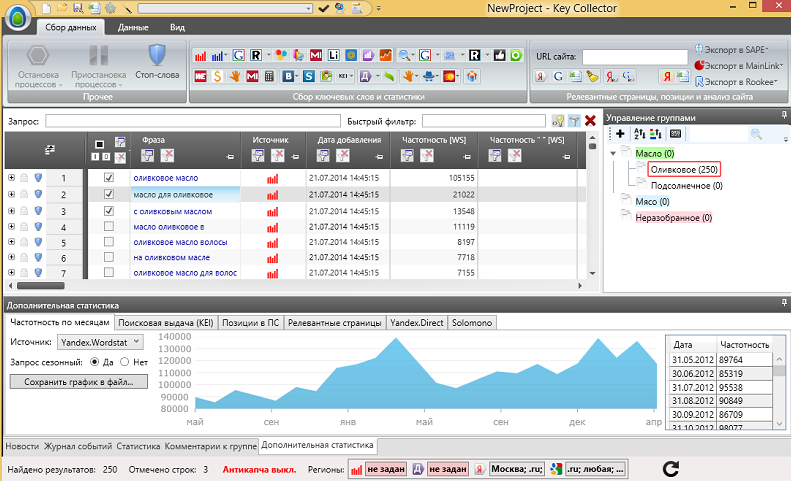
Процесс сбора ключевых слов из Wordstat и сбор поисковых подсказок абсолютно идентичен тому, что реализован в Словоёбе. Однако, сбор частот реализован двумя способами – через Wordstat (как в Словоёбе) и через Директ. Через Директ сбор частот ускоряется в несколько раз.
Делается это следующим образом: нажимаем на кнопку Д (сокращение от «Директ», ставим галочку о заполнении колонок статистики Wordstat, проставляем галочки (при необходимости) о том, какую именно частоту мы хотим получить (базовую, в кавычках, или в кавычках и с восклицательными знаками», нажимаем «Получить данные» и ждем окончания сбора.

Сбор через данных Яндекс.Директ занимает гораздо меньше времени, чем через Wordstat. Однако, тут есть и один минус – статистика может быть собрана не по всем ключам (например, если ключевая фраза слишком длинная). Однако, этот минус компенсируется сбором данных из Wordstat.
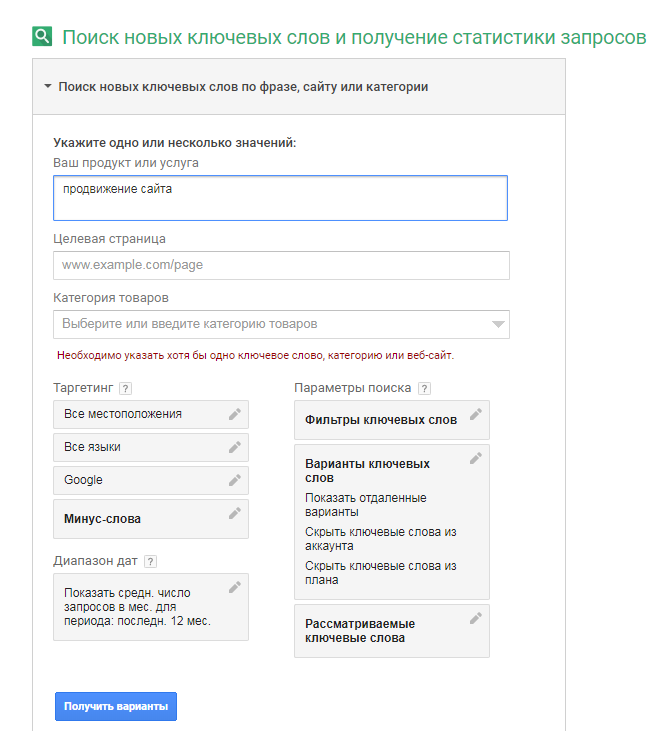
Планировщик ключевых слов Google
Данный инструмент крайне полезен для сбора ядра с учетом нужд пользователей поисковой системы Google.
С помощью Планировщика ключевых слов Google можно найти новые запросы по запросам (как бы странно это ни звучало), и даже сайтам/тематикам. Ну а в качестве бонуса можно даже прогнозировать трафик и комбинировать новые поисковые запросы.
По имеющимся запросам статистику можно получить, выбрав соответствующую опцию на главной странице сервиса. При необходимости можно выбрать регион и минус-слова. Результат будет выведен в CSV-формате.
Как узнать семантическое ядро сайта конкурента
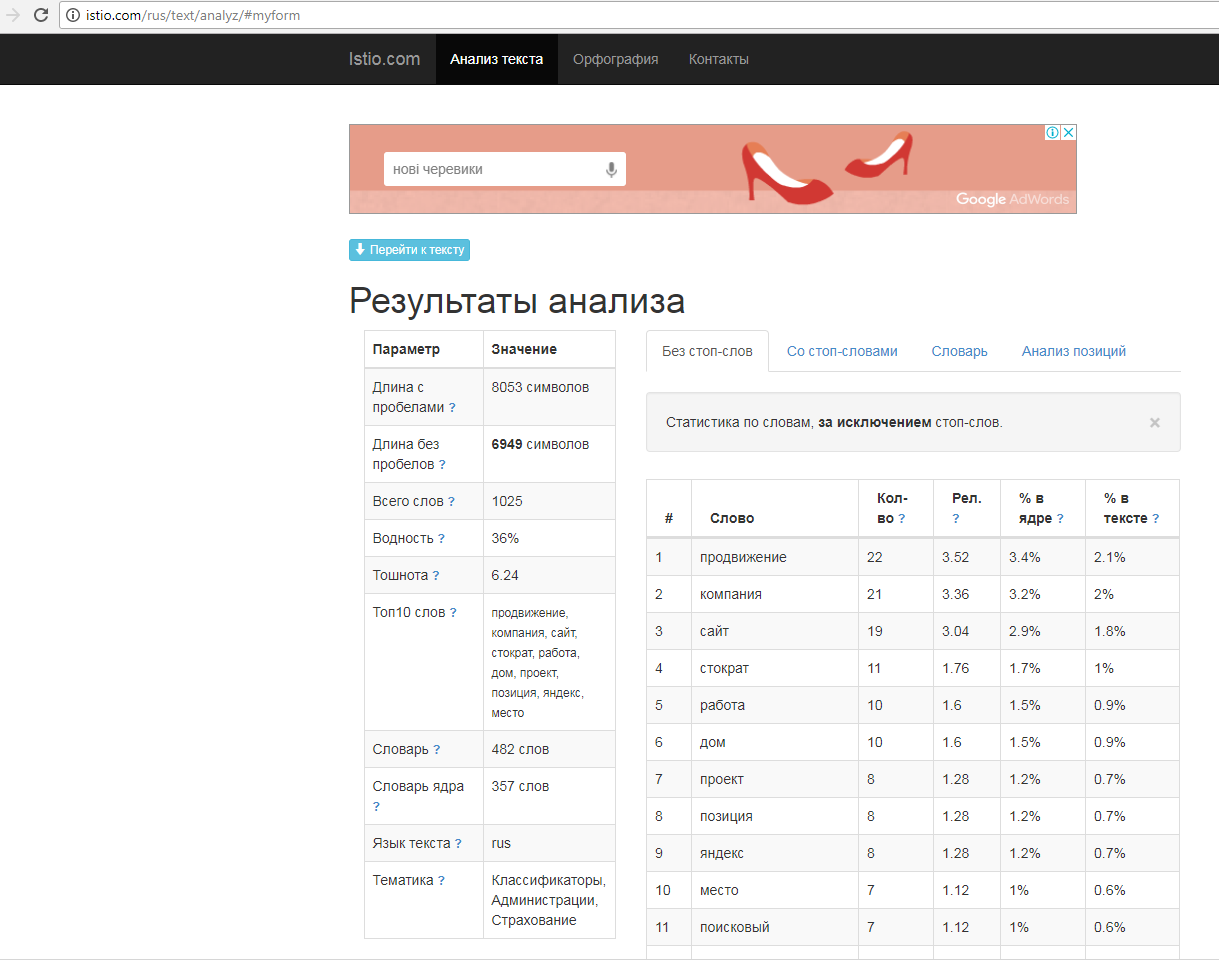
Конкуренты могут нам быть еще и друзьями, т.к. у них можно позаимствовать идеи по подбору ключевых слов. Практически по каждой странице можно получить список ключевых слов, под которые она оптимизирована, причем вручную.
Первый способ – изучить контент страницы, мета-теги Title, Description, H1 и KeyWords. Можно сделать всё вручную.
Второй способ – воспользоваться сервисами Advego или Istio. Для анализа конкретно взятых страниц этого вполне достаточно.
Если же требуется произвести комплексный анализ семантического ядра сайта, то имеет смысл воспользоваться более мощными инструментами:
- SEMrush
- Searchmetrics
- SpyWords
- Google Trends
- Wordtracker
- WordStream
- Ubersuggest
- Топвизор
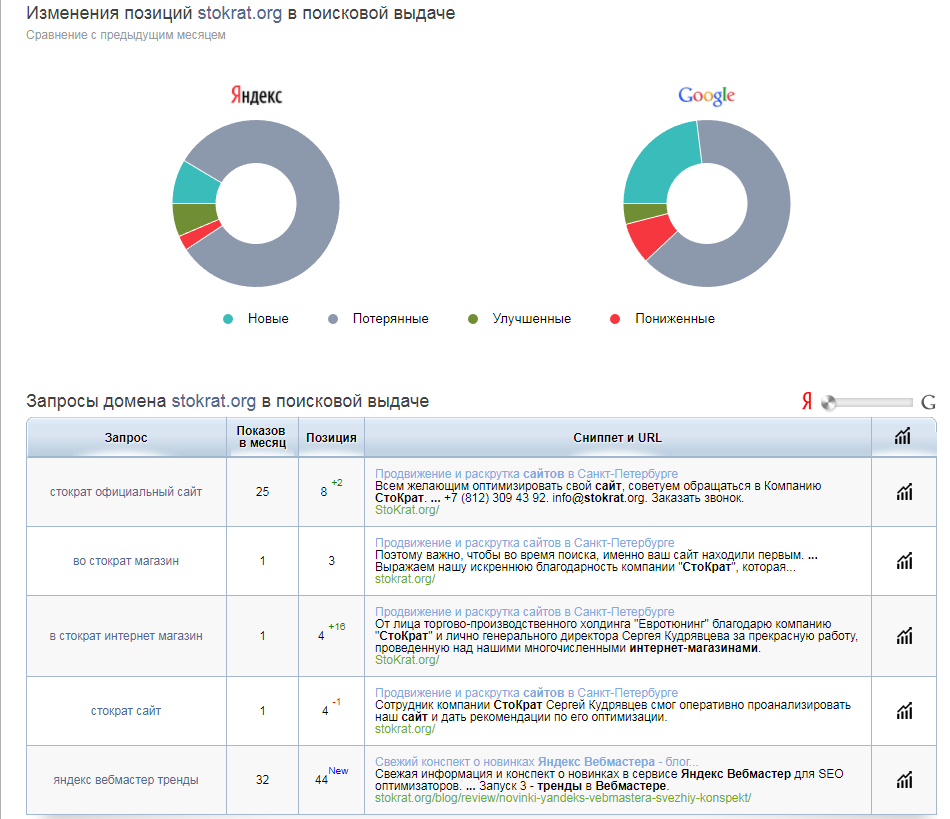
Однако, приведенные выше инструменты больше подходят для тех, кто занимается профессиональным продвижением нескольких сайтов одновременно. «Для себя» даже ручного способа будет вполне достаточно (в крайнем случае – Advego).
Ошибки при составлении семантического ядра
Самая частая ошибка – очень маленькое семантическое ядро
Разумеется, если это какая-то узкоспециализированная ниша (например, ручное изготовление элитных музыкальных инструментов), то ключей при любом раскладе будет мало (сотня-полторы-две).
Чем больше семантическое ядро (но без «мусора») – тем лучше. В некоторых нишах семантическое ядро может состоять из нескольких… МИЛЛИОНОВ ключей.
Вторая ошибка – синонимайзинг. Точнее – его отсутствие
Вспомните пример с Анталией. Ведь в данном контексте «туры» и «путевки» - это одно и то же, но эти 2 списка ключей могут кардинально отличаться. «Стриппер» вполне могут искать по запросу «зачистка для проводов» или «инструмент для удаления изоляции».

Внизу поисковой выдачи у Google и Яндекса есть вот такой блок:
Именно там зачастую и можно подсмотреть синонимы.
Составление семантического ядра исключительно из ВЧ-запросов
Вспомните, что мы в начале поста говорили о низкочастотных запросах, и вопрос «а почему это ошибка?» у Вас больше не возникнет. Низкочастотные запросы как раз и будут приносить основную долю трафика.
«Мусор», т.е. нецелевые запросы
Необходимо удалить из собранного ядра все запросы, которые Вам не подходят. Если у Вас магазин сотовых телефонов, то для Вас запрос «продажа сотовых телефонов» будет целевым, а «ремонт сотовых телефонов» - мусорным. В случае с сервисным центром по ремонту сотовых телефонов все с точностью до наоборот: «ремонт сотовых телефонов» - целевой, а «продажа сотовых телефонов» - мусорный. Третий вариант – если у Вас магазин сотовых телефонов, к которому «прикреплен» сервисный центр, то оба запроса будут целевыми.
Еще раз – мусора в ядре быть не должно.
Отсутствие группировки запросов
Разбивать ядро на группы строго обязательно.
Во-первых, это позволит составить грамотную структуру сайта.
Во-вторых, не будет «ключевых конфликтов». Например, возьмем страницу, которая продвигается по запросам «купить наливной пол» и «купить ноутбук acer». Поисковая система может прийти в замешательство. В итоге продвижение сайта будет провалено по обоим ключам. А вот по запросам «ноутбук hp 15-006 купить» и «ноутбук hp 15-006 цена» уже имеет смысл продвигать одну страницу. Более того, не просто «имеет смысл», а будет единственным правильным решением.
В-третьих, кластеризация позволит прикинуть сколько страниц еще нужно создать, чтоб ядро было охвачено полностью (а главное – нужно ли?).
Ошибки в разделении коммерческих и информационных запросов
Основная ошибка в том, что коммерческими могут оказаться и запросы, в которых нет слов «купить», «заказать», «доставка» и т.п.
Например, запрос «». Как определить, коммерческий это запрос, или информационный? Очень просто – смотрим поисковую выдачу.
Google нам говорит, что это коммерческий запрос, т.к. в выдаче у нас первые 3 позиции занимают документы со словом «купить», а на четвертой позиции хоть и расположились «отзывы», но взгляните на адрес – это достаточно известный интернет-магазин.

А вот с Яндексом все оказалось не так просто, т.к. в ТОП-5 у нас 3 страницы с обзорами/отзывами и 2 страницы с торговыми предложениями.

Тем не менее, данный запрос все-таки относится к коммерческим, т.к. коммерческие предложения есть и там, и там.
Однако, есть и инструмент для массовой проверки ключей на «коммерцию» - Semparser.
Подобрали «пустые» запросы
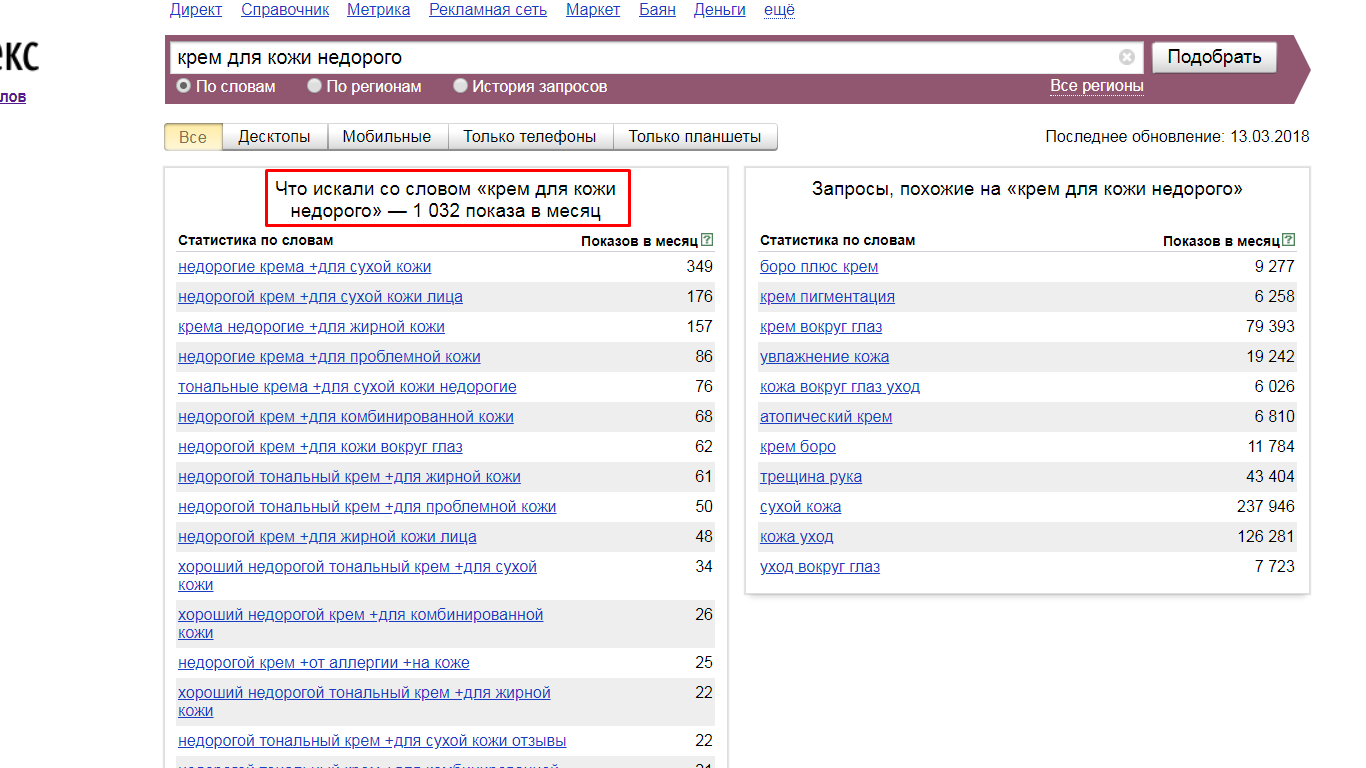
Частоты необходимо собирать и базовые, и в кавычках. Если частота в кавычках равна нулю – запрос лучше удалить, т.к. это пустышка. Нередко бывает даже так, что базовая частота превышает несколько тысяч показов в месяц, а частота в кавычках – нулевая. И сразу же конкретный пример - ключ «крем для кожи недорого». Базовая частота 1032 показа. Выглядит вкусно, правда?
Но весь вкус теряется, если пробить эту же фразу в кавычках:
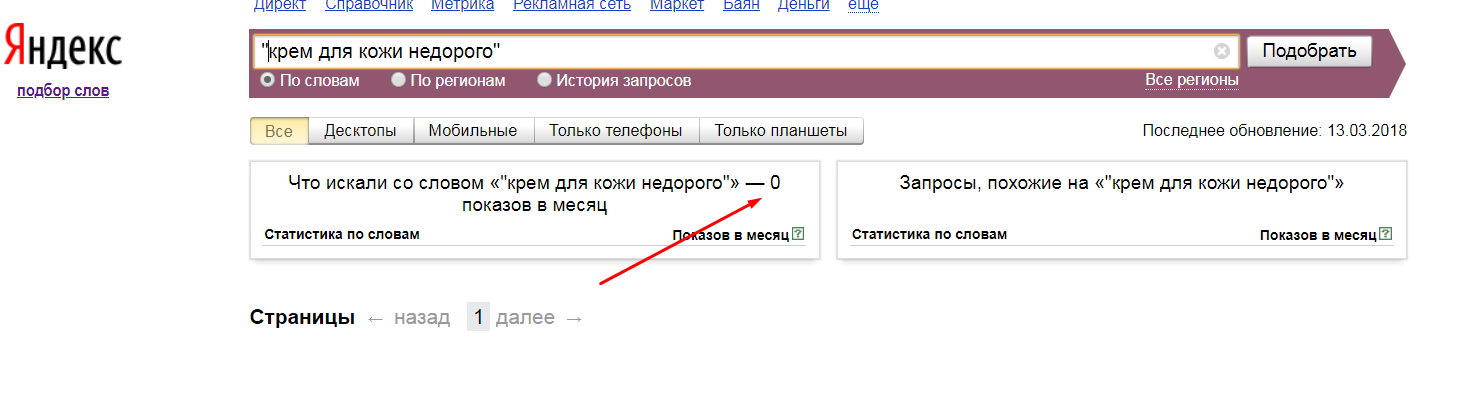
Не все пользователи печатают без ошибок. Из-за них «кривые» ключевые запросы в базу и попадают. Включать их в семантические ядро бессмысленно, поскольку поисковые системы все равно перенаправляют пользователя на «исправленный» запрос.

И с Яндексом ровно то же самое.
Так что «кривые» запросы (даже если они высокочастотные) удаляем без сожаления.
Пример семантического ядра сайта
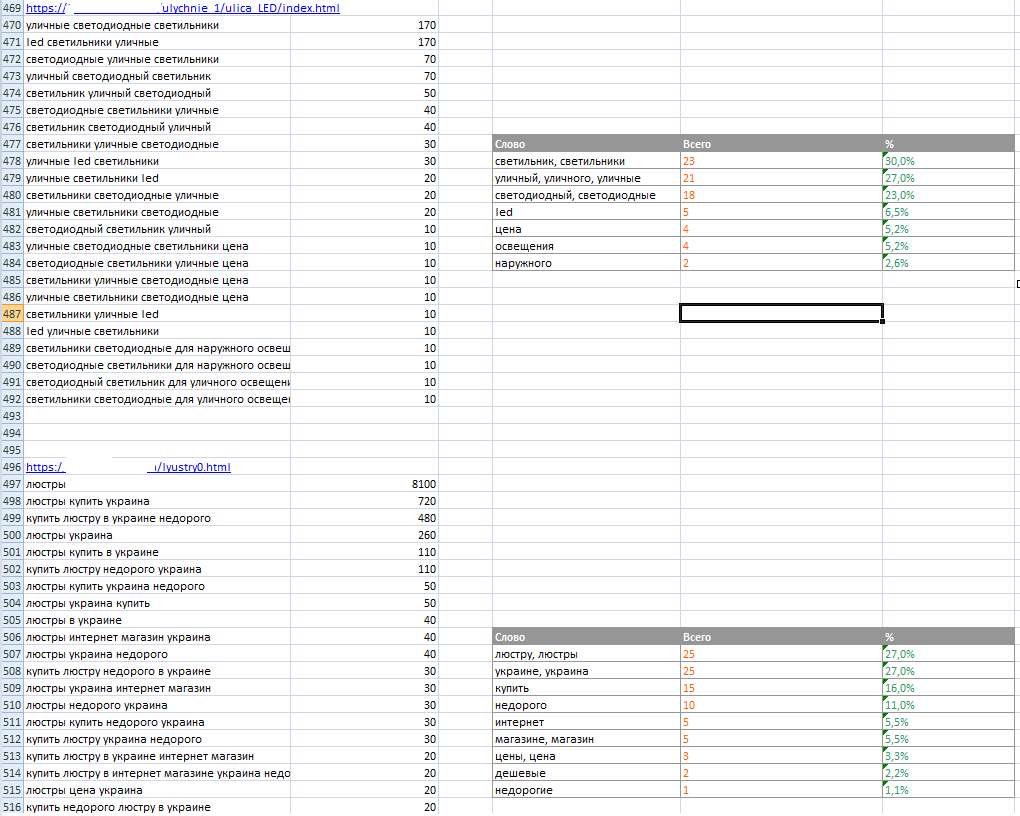
Теперь переходим от теории к практике. После сбора и кластеризации семантическое ядро должно выглядеть примерно вот так:
Итог
Что же нам требуется для составления семантического ядра?
- хотя бы немного мышления бизнесмена (или хотя бы маркетолога)
- хотя бы небольшие навыки оптимизатора.
Еще раз:
- важно уделить особое внимание структуре сайта
- прикиньте, по каким запросам пользователи могут искать нужную им информацию
- на основе «прикидок» собираете список наиболее подходящих запросов (Яндекс.Wordstat + Wordstat Assistant, Словоёб, Key Collector, Планировщик ключевых слов Google), частоты с учетом словоформ (без кавычек), а также без учета (в кавычках), удаляете «мусор».
- собранные ключи необходимо сгруппировать, т.е. распределить по страницам сайта (даже если эти страницы еще не созданы).
Нет времени? Обращайтесь к нам, мы сами все за Вас сделаем!





