СОДЕРЖАНИЕ
Поиск страниц, на которых минимум 2 заголовка H1
Используются ли атрибуты alt для картинок?
Проверка карты сайта на корректность
Немногим ранее мы выпустили целый обзор на программу Screaming Frog Seo Spider. Сегодня же мы поговорим больше о практической части. Например, о том, как с помощью данной программы провести экспресс-аудит сайта.
Но перед тем как мы начнем, хотим предупредить вот о чем:
- чем больше документов на сайте – тем больше времени потребуется на его сканирование (в некоторых случаях на сканирование может уйти несколько дней);
- на очень крупных сайтах программа может начать вести себя нестабильно, причем настолько, что компьютер может начать лагать (именно компьютер, а не программа).
Именно поэтому хотя бы 1 раз в несколько часов необходимо ставить сканирование на паузу и делать сохранение проекта.
Примечание автора: лично у меня комп собран на базе 6-ядерного Intel Core i5 8400 + 16 Гб оперативки на 2,4 гГц, т.е. ресурсов, по идее, для такой программы должно хватать с запасом, но нифига. Поручили мне как-то просканировать сайт на несколько миллионов страниц, это был сущий ад. Лаги были такие, что даже мышка двигалась с опозданием в 5-6 секунд, работать было просто невозможно. В итоге закончилось всё тем, что Frog вообще завис и потом вылетел. И это уже после того, как было отсканировано 1,5 миллиона страниц, а на это ушло, мягко говоря, несколько часов. В итоге пришлось сканировать сайт заново. И это, повторюсь, на 6-ядерном Core i5 с 16 Гб оперативки, а это далеко не печатная машинка.
А вот теперь переходим к делу.
Сканирование сайта
Первым делом заходим в меню Mode и ставим галочку Spider (на приведенном ниже скриншоте пункты деактивированы, поскольку сканирование уже запущено). Далее указываем адрес сайта (желательно не с https, а с http – это позволит «не отходя от кассы» проверить наличие переадресации с http на https). И осталось только запустить сканирование нажатием на кнопку Start (на скриншоте эта кнопка заменена на кнопку постановки на паузу, поскольку сканирование уже запущено).
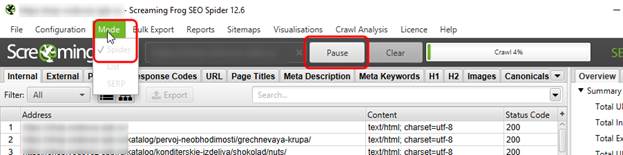
Что за сайт был просканирован – мы показывать не будем по понятным причинам. Упомянем лишь, что владелец сайта – наш клиент. Тем не менее, результаты сканирования нам расскажут очень о многом.
Ищем битые ссылки
Для поиска битых ссылок переходим на вкладку «Response Codes» (Коды ответа) и выставляем фильтр «Client Error 4xx». И на выходе получаем небольшое количество битых ссылок:
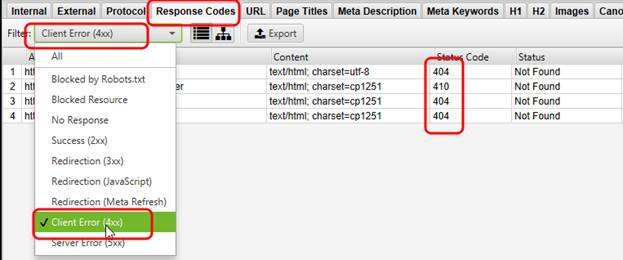
В списке всего 4 битые ссылки. Поскольку адресов не видно, заспойлерим, что внутренняя ссылка только одна и ведет на страницу 404. Остальные 3 ссылки являются внешними.
Из этого следует простейший вывод:
1) ссылки, которые ведут на сторонний сайт, вряд ли будут восстановлены, а потому их необходимо удалять с сайта;
2) если присутствует страница 404, значит на нее кто-то ссылается.
Чтобы узнать, кто ссылается на страницу 404, выделяем эту страницу в списке,
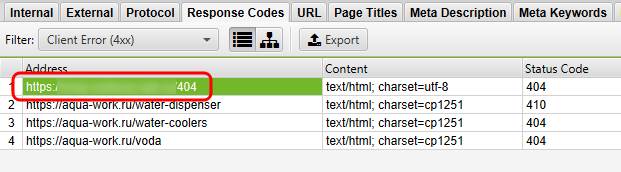
далее внизу переходим на вкладку Inlinks и…
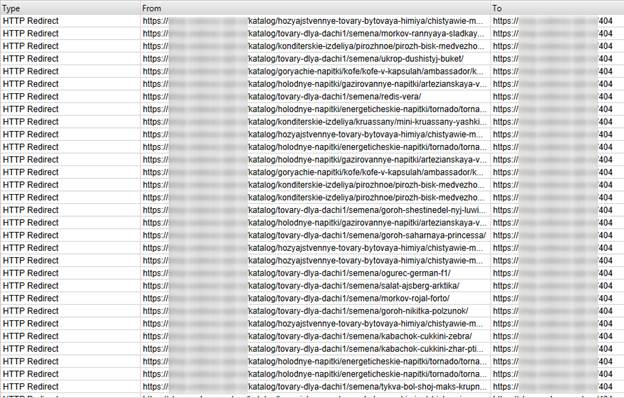
… и видим, что на эту страницу ссылается просто овер как много других страниц. А если точнее – происходит переадресация с этих страниц на страницу 404, о чем свидетельствует статус HTTP Redirect в первом столбце. А это значит, что эти ссылки тоже битые. Но как их найти, ведь тут настроена переадресация?
Очень просто:
1) ищем столбец «Redirect URL» и сортируем (тогда все редиректы на страницу 404 будут идти друг за другом);
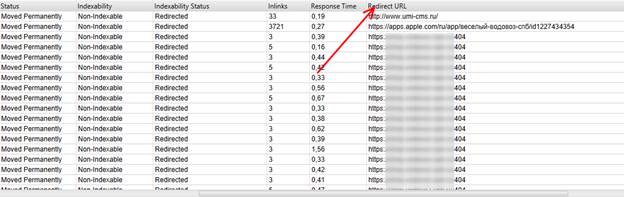
Для большего удобства этот столбец можно мышкой перетащить так, чтобы он располагался рядом со столбцом «Address».
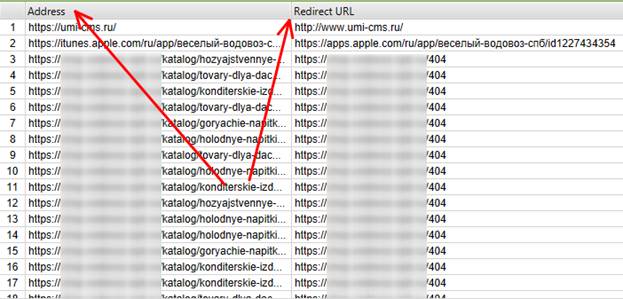
2) далее выделяем диапазон строк, в которых присутствуют редиректы на страницу 404, идём во вкладку Inlinks и смотрим истинные источники:
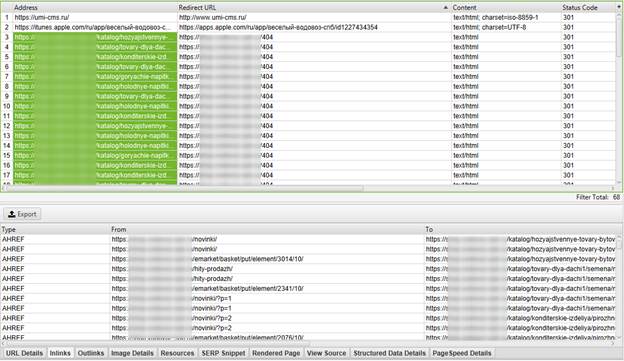
Для тех, кто не понял, еще раз и чуть подробнее. Внизу в столбце From будут страницы, на которых размещены битые ссылки. В столбце To – ссылки, те самые ссылки, с которых происходит переадресация на страницу 404.
Согласны, получилось несколько мудрёно, но это на словах. На практике всё гораздо проще.
С битыми ссылками, которые еще и внешние, ситуация проще – там нет переадресации на страницу 404, а потому можно СРАЗУ отследить, где она расположена.

В любом случае, одна из проблем сайта уже выявлена – большое количество битых ссылок, которые необходимо удалять или исправлять.
Ищем дубли мета-тегов
Как мы уже говорили в одной из прошлых статей, дублирование мета-тегов Title, H1 и Description не допускается. И сейчас мы покажем, как после сканирования (и сохранения проекта) можно оперативно найти дубли мета-тегов.
Самое первое, что нужно сделать – экспортировать данные в Excel. Для этого переходим на вкладку Internal, ставим фильтр HTML, нажимаем кнопку Export и выбираем место для сохранения.
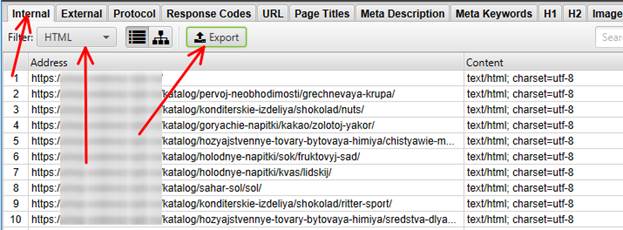
Далее комбинацией клавиш Ctrl+A выделяем всё. Далее сортируем столбец Indexability от А до Я – это необходимо для того, чтобы неиндексируемые страницы можно было сразу отсечь. Если страница не индексируется, то там уже глубоко по ящику, какие на ней мета-теги.
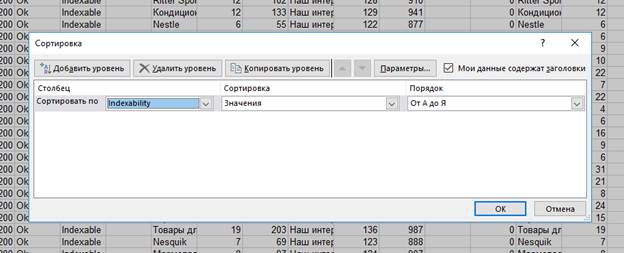
Далее с клавиатуры нажимаем F3 или Ctrl+F, вводите non-index и нажимаете «Искать далее». Таким нехитрым манёвром Вас перекинет на первую строку, в которой вместо Indexable будет Non-Indexable.
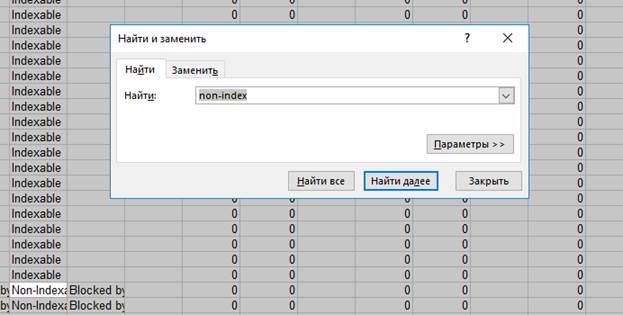
Далее выделяем и удаляем все строки, в которых в столбце Indexability присутствует Non-Indexable. С оставшимися строками мы и будем работать.
К слову, столбцы тоже нужны не все. Для удобства можно удалить все столбцы, кроме Address, Title 1, Meta Description 1 и H1-1.
Далее необходимо отсортировать от А до Я тот столбец, в котором Вы планируете искать повторы. Например, Title.
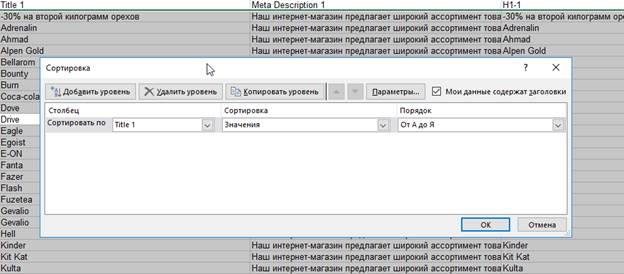
Далее в ближайшем свободном столбце прописываем следующую формулу:
=ЕСЛИ(B2=B1; "СОВПАДЕНИЕ"; ЕСЛИ(B2=B3; "СОВПАДЕНИЕ"; ""))
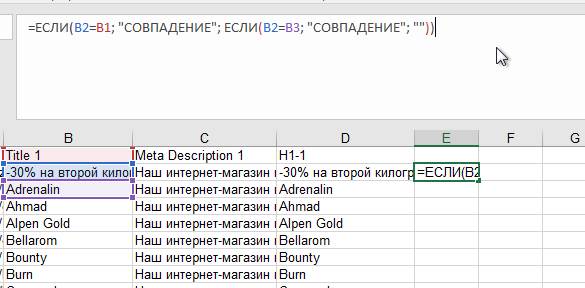
Данная формула проверяет, совпадает ли у заданной ячейки значение с ячейкой, которая на строку выше и с ячейкой, которая на строку ниже. Если совпадение есть – формула об этом сообщает. Если нет – молчит. Желательно столбец с формулой как-то озаглавить, чтобы не было мешанины при сортировке. Всё, что осталось – «протянуть» формулу вниз до самого конца таблицы.
Далее снова через Ctrl+A выделяем всю таблицу и сортируем по обратному алфавитному порядку последний столбец – это необходимо для того, чтобы все «совпадения» «переехали» в первые строки таблицы.
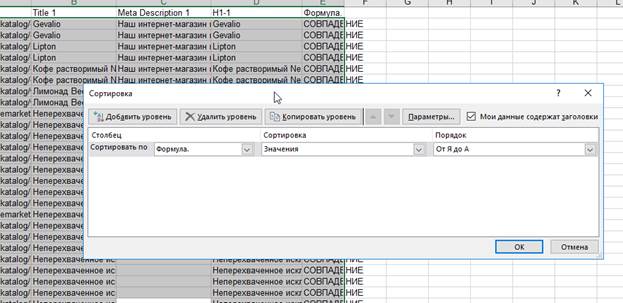
И в данном случае мы видим, что совпадений просто овер-предостаточно. Естественно, вся эта информация должна быть занесена в аудит.
В реальной жизни с момента экспорта файла процедура поиска совпадающих Title занимает примерно 40 секунд. Ровно по этой же схеме можно найти совпадающие Description и H1. Поэтому останавливаться на этом уже не будем.
Поиск Title=H1
Если коротко и на пальцах, то всё полностью аналогично предыдущей части статьи. Единственное отличие – используемая в Excel’е формула:
=ЕСЛИ(B2=D2; "СОВПАДЕНИЕ"; "")
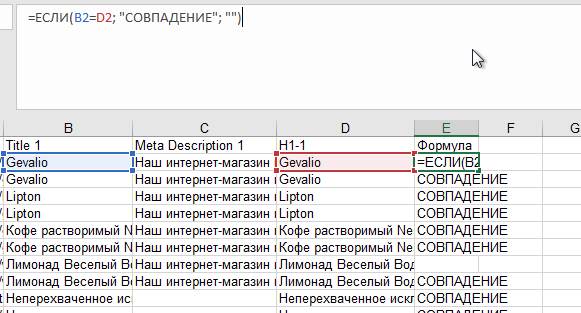
Данная формула проверяет ячейки столбца Title и H1, находящиеся на одной строке. Если совпадение есть – формула об этом сообщает. Если нет – молчит.
И далее то же самое – сортируем последний столбец в обратном алфавитном порядке и заносим информацию в аудит.
Проверка длины мета-тегов
В одной из статей мы писали, что длина мета-тегов супербольшой роли не играет, поскольку поисковые системы уже давно научились выводить мета-теги частично (речь о Title и Description). И мы продолжаем придерживаться данной теории, но с одним условием – мета-теги не должны быть слишком короткими. Согласитесь, когда Title состоит всего из одного слова (а по предыдущим скриншотам Вы убедились, что такое бывает) – это выглядит, мягко говоря, так себе.
Именно поэтому поговорим о том, как оперативно выявить короткие мета-теги.
Покажем на примере Title, для чего открываем ранее экспортированный файл (или экспортируем его заново) и удаляем все столбцы, кроме Address, Title 1, Title 1 Length и аналогичных столбцов по Description и H1.
Далее в свободном столбце прописываем формулу:
=ЕСЛИ(C2<75; "МАЛО!!!"; "")
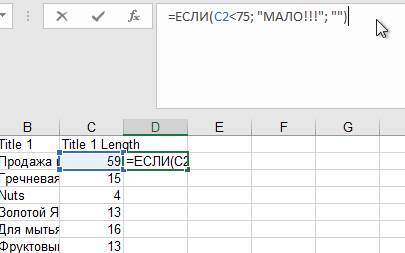
Данная формула сообщает, что Title слишком короткий, если его длина менее 75 знаков и молчит, если равно 75 и более. Всё, что осталось – «протянуть» формулу по всему столбцу и отсортировать по последнему в порядке, обратном алфавитному.
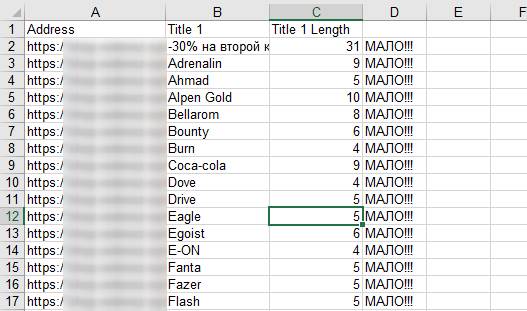
По аналогии можно:
- выявить слишком короткие Description (только вместо 75 будет уже 140 знаков);
- выявить слишком короткие H1.
Схема одна и та же, просто будет чуть-чуть отличаться формула.
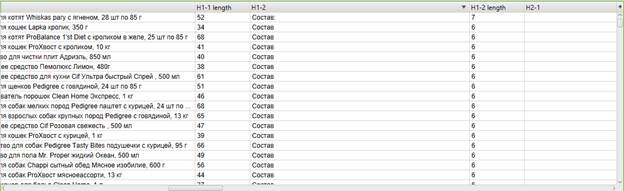
Поиск страниц, на которых минимум 2 заголовка H1
Вот это, пожалуй, одна из самых простых задач, которую можно оперативно выполнить с помощью Screaming Frog SEO Spider. Достаточно просто убедиться, что в таблице присутствует столбец H1-2. Если присутствует – значит на сайте действительно присутствуют страницы, на которых минимум 2 H1-заголовка. Просто кликаем по заголовку столбца до тех пор, пока все «вторые» H1-заголовки не окажутся вверху таблицы. Всё – Mission Completed.
Используются ли атрибуты alt для картинок?
Хороший вопрос! Особенно в современных реалиях, когда этот тег мало кто использует, ибо это достаточно трудозатратно. Проверяется это достаточно просто.
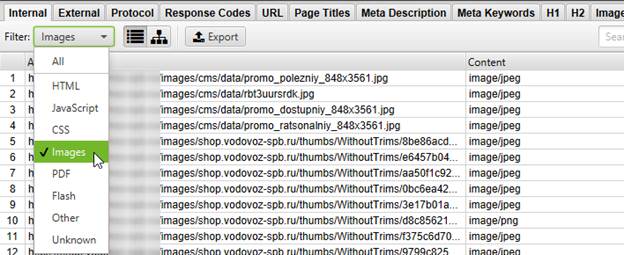
Первым делом необходимо выставить фильтр Images, чтобы из таблицы было скрыто всё, кроме картинок.
Далее нажимаем Ctrl+A, чтобы выделить всю таблицу. После этого в нижнем «разделе» программы выбираем вкладку Inlinks, ищем на ней столбец Alt Text и сортируем.
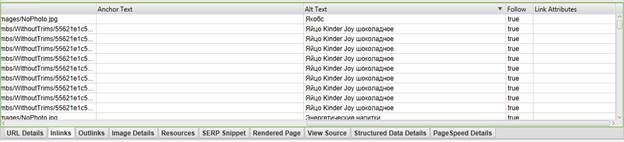
Как видите, в нашем случае теги alt присутствуют. Хотя, если честно, присутствуют не на всех страницах, но это мы поправим.
Если же Вы хотите выяснить, на каких страницах находятся картинки без alt’ов, то сортируем столбец Alt Text так, чтобы в первых строках было пусто, а потом смотрим содержимое столбцов From и To. В столбце From будет располагаться адрес страницы, на которой присутствуют картинки без alt’ов, а в столбце To – ссылки на эти картинки.
Проверка карты сайта на корректность
И сразу же оговорка – в данном случае под «корректностью» подразумевается не формат, а актуальность – все ли индексируемые страницы присутствуют, есть ли битые ссылки и т.д.
Для этих целей на вкладке Internal ставим фильтр HTML, сортируем столбец Indexability так, чтобы индексируемые страницы были сверху и копируем в Excel список имеющихся в таблице индексируемых УРЛов.
Далее сохраняем проект и перезапускаем программу без открытия нового проекта. Затем скачиваем карту сайта с сайта и открываем ее в Excel.
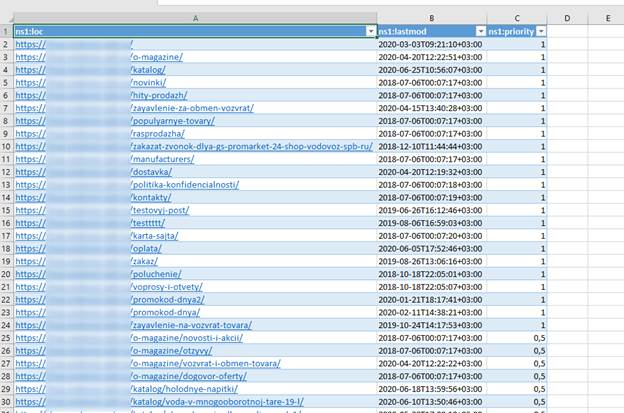
Далее копируем УРЛы и вставляем их в документ, куда были вставлены УРЛы из Screaming Frog.
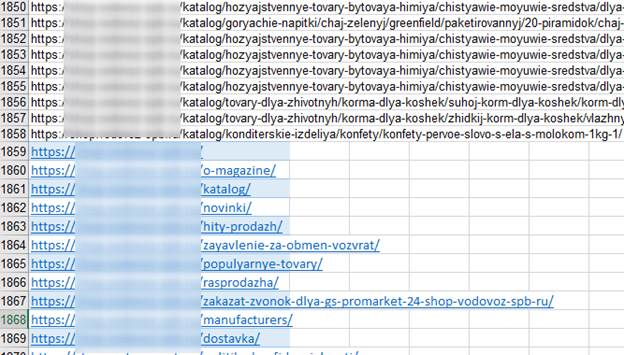
После заходим на вкладку «Данные» и жмем «Удалить дубликаты».
Вверху (не окрашенные) будут находиться те, которые мы вставили из Screaming Frog’а, а внизу (окрашенные) останутся те, которые в Screaming Frog’е почему-то отсутствуют. Копируем окрашенные УРЛы в буфер обмена.
Далее возвращаемся в Screaming Frog, заходим в меню Mode и ставим галочку List – таким образом мы будем сканировать уже не сайт целиком, а вполне конкретные его страницы.
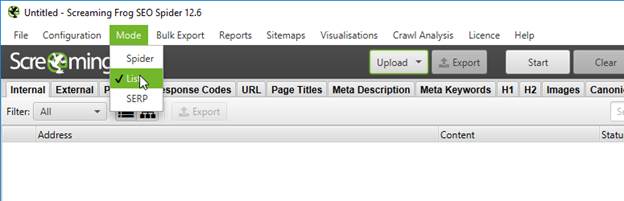
Далее нажимаем Upload – Paste. После этого в программу будут вставлены те УРЛы, которые были ранее скопированы в буфер обмена. После вставки сразу же запустится их сканирование.
В нашем случае УРЛов мало – всего 98. Именно на столько УРЛов не сходится карта сайта с тем, что ранее отсканировал Screaming Frog.
И вот результаты:
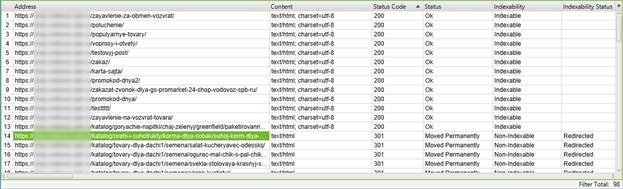
Что же мы имеем?
1) очень много 301 редиректов – им в карте сайта не место, а потому их нужно убрать;
2) присутствует тестовая страница, которой в карте сайта тоже не место.
Присутствие же остальных страниц в карте сайта вполне обосновано.
Итоги
Абсолютно на всё, о чем сейчас было рассказано, уходит в среднем 5-10 минут, если мы говорим именно об анализе, а не о его документировании.
А ведь мы почти ничего не сделали, но в то же время получили просто огромное количество полезной информации о состоянии сайта. Мы выявили, что у нашего клиента:
- присутствуют битые ссылки;
- присутствуют битые ссылки, с которых перебрасывает на страницу 404;
- присутствуют внешние ссылки;
- присутствуют страницы, на которых Title = H1;
- присутствуют страницы, на которых слишком короткие Title и H1;
- присутствуют страницы, на которых Title = Title другой страницы;
- присутствует куча редиректов, без которых вполне можно обойтись;
- присутствует тестовая страница;
- присутствуют страницы, на которых тег alt для картинок не используется.
После документирования этот объем данных потянет страниц на 20, а выявлено всё это за каких-то 5 минут.
Деваться некуда – придется лечить.





