СОДЕРЖАНИЕ
Причины возникновения дублей страниц, лечение
Чем опасны дубли страниц на сайте?
В среде SEO «дублями» принято называть абсолютно идентичные документы, которые доступны по разным адресам. Хотя, правильнее сказать, не «идентичные документы», а просто «документ». Т.е. физически документ один, а адресов, по которым он доступен – много. Следовательно, если внести какие-то изменения в этот документ, то изменения будут отражены по всем адресам.
Наличие дублей – это почти всегда плохо, поскольку:
- затрудняется индексирование сайта поисковым роботом;
- поисковой системе трудно определить, какая из страниц наиболее релевантна запросу (невольно вспоминается осёл, который не может выбрать между двумя одинаковыми морковками, находящимися от него на одинаковом расстоянии);
- за обильное количество дублей поисковая система может пессимизировать сайт, а в качестве бонуса – даже наложить санкции.
Следовательно, от дублей необходимо избавляться.
Для начала отметим, что причин появления дублей может быть огромнейшее количество, начиная с особенностей CMS, ошибок вебмастеров и заканчивая «да-да, всё нормально, так и задумывалось». Более того, бывают ситуации, когда наличие дублей на сайте является не просто нормой, а вообще единственным правильным решением.
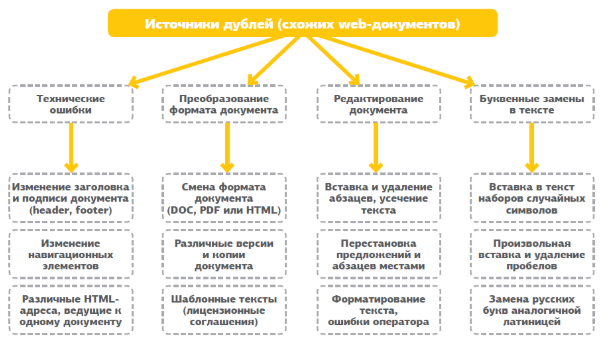
В этой статье мы рассмотрим только технические причины, а также способы их устранения, т.к. именно по техническим причинам в 98% случаев дубли и появляются. Оставшиеся 2% - это либо кража контента, либо «так и задумывалось», либо что-то еще в этом роде.
Обратите внимание, что лечение сайта от дублей гарантированно влечёт за собой образование «битых» ссылок. Поэтому лечение сайта должно быть одновременно и от дублей, и от «битых ссылок».
Какие существуют виды дублей
В среде SEO принято делить дубли на «полные» и «неполные».
С полными дублями всё просто – там совпадает абсолютно все, кроме адреса (всегда) и «хлебных крошек» (не всегда). Такое вполне может быть, скажем в интернет-магазинах, когда одна и та же карточка товара дублируется в несколько разделов. Другая ситуация – если движок автоматически генерирует дубли. В обоих случаях сайт необходимо лечить (как – будет рассказано позже).
С неполными дублями все немного сложнее, т.к. дублируется только часть контента. Это тоже крайне распространенная ситуация. Вот пара примеров:
1) Те же карточки товаров. Например, Вы продаёте газовые плиты, которые бывают без электророзжига, с электророзжигом от батарейки и с электророзжигом от 220В. Следовательно, Вам необходимо подготовить 2 маленьких текста – один для плит с розжигом от батареек, второй – с розжгом от 220В. Затем, чтобы не перепечатывать одно и то же по 100 раз, эти 2 фрагмента просто дублируют в различные карточки товаров. Поисковые системы при этом прекрасно понимают, что разные товары могут обладать одними и теми же характеристиками. Именно поэтому такой подход с частичным дублированием текста является самым правильным. Никаких мер по лечению сайта в этом случае не требуется.
2) Блог. Для примера возьмем блог нашего Уважаемого коллеги (хоть и не из нашего агентства) Алексея Трудова. Заходим на главную и видим, что она представляет собой просто «ленту» последних записей.
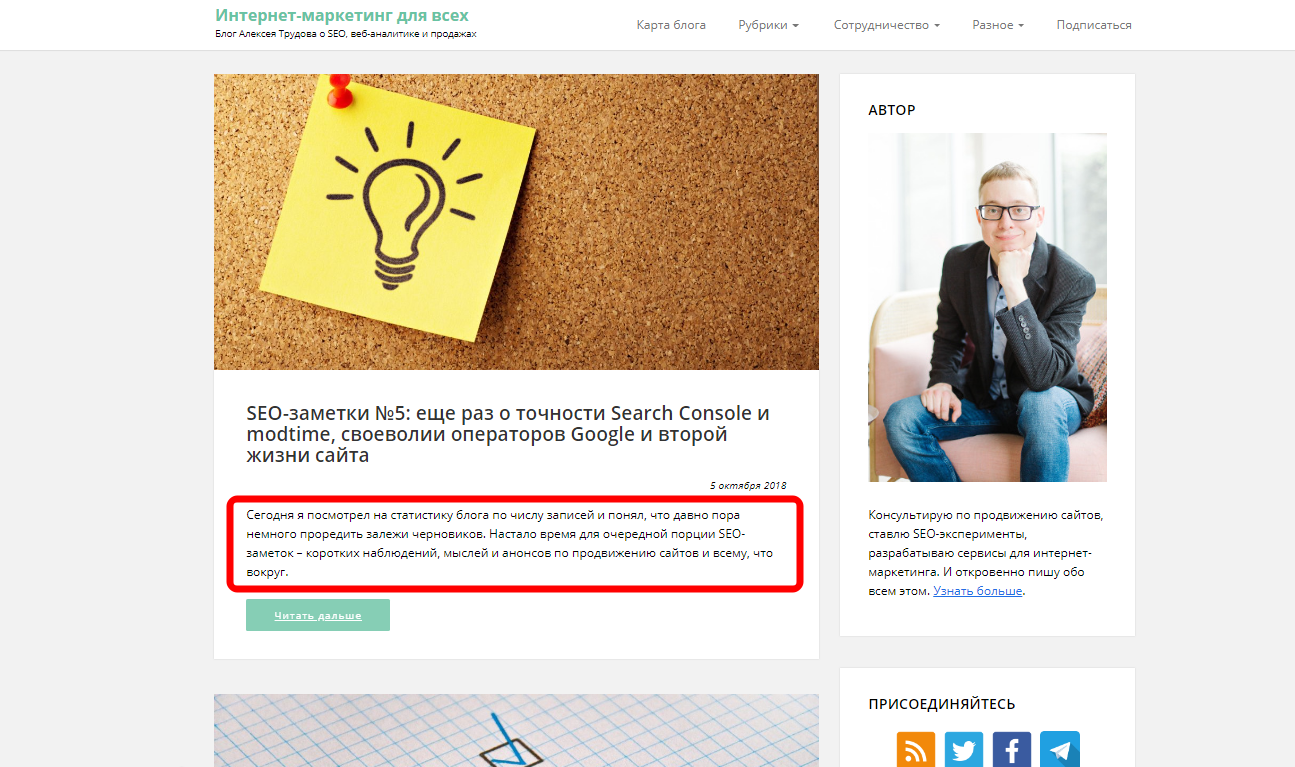
Обратите внимание на фрагмент текста, который выделен красным. Если открыть статью, то именно с этого текста она и будет начинаться. Следовательно, главная страница блога является неполным дублем всех записей сайта.
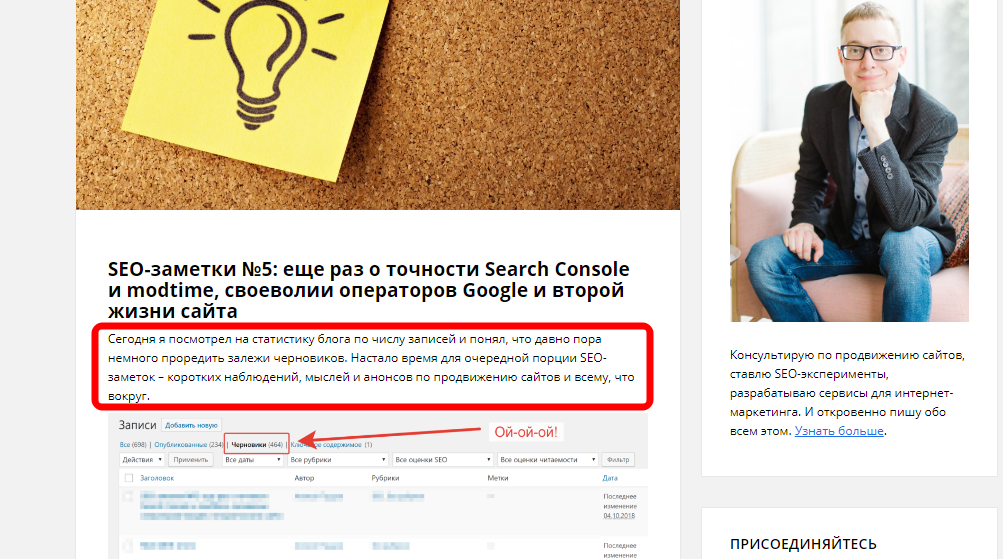
В данном случае в лечении сайта тоже нет необходимости, поскольку для этого придется закрывать от индексирования главную страницу сайта, а этого делать не хотелось бы.
Причины возникновения дублей страниц, лечение
Существует 4 основные причины возникновения дублей страниц:
Причина 1 – Одна и та же запись в нескольких разделах. Адреса дублей, как правило, выглядят примерно вот так:
wiki.site.ru/blog1/info/
wiki.site.ru/blog2/info/
Также стоит отметить, что сегодня очень много сайтов настроено на «сокращенные» ЧПУ, поэтому возможен и третий вариант - wiki.site.ru/info/, т.е. раздел в УРЛ уже не указывается. За счет такой настройки ЧПУ данная ситуация стала встречаться все реже и реже.
Если же у Вас ситуация с первыми двумя вариантами адреса, то сайт можно вылечить двумя способами:
- настроить переадресацию с wiki.site.ru/blog1/info/ на wiki.site.ru/blog2/info/ (или наоборот) с кодом ответа 301;
- добавить в код документа параметр rel="canonical", например, вот так: <link rel="canonical" href=" wiki.site.ru/blog1/info/" />. Таким образом, Вы прямым текстом сообщаете поисковым системам «это дубль, а оригинал вон там». Если же адрес документа и адрес в коде совпадают – ничего страшного.
Атрибут rel="canonical" изначально был введён поисковой системой Google примерно в 2008-2010 году (точно не помним), т.е. достаточно давно. На сегодняшний момент, помимо Google, данный тег читается еще и Яндексом.
Технические дубли. Этим грешат почти все движки – кто-то больше, кто-то меньше. Наиболее активно этим грешат Joomla и 1С-Битрикс. Фишка в том, что в адресную строку добавляются некоторые параметры (т.е. вопросительный знак и всякая лабуда, идущая за ним), которые никак не влияют на содержимое страницы. УРЛы в этом случае могут выглядеть примерно вот так:
обычный: site.ru/rarticles.php
с динамическими параметрами site.ru/rarticles.php?ajax=Y
В подавляющем большинстве случаев лечение ограничивается добавлением в robots.txt строк, запрещающих индексирование страниц с динамическими параметрами. Однако, такой способ уместен только тогда, когда используются ЧПУ.
ВАЖНО!!!
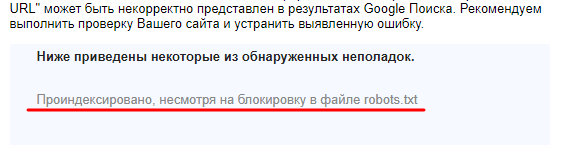
В файле robots.txt прописываются не законы, а РЕКОМЕНДАЦИИ. Говоря простым языком, если страница запрещена к индексированию в robots.txt, она всё равно может быть проиндексирована поисковыми системами. В этом случае в Google Search Console Вы получите вот такое уведомление:
Например, WordPress можно настроить так, чтобы вместо ЧПУ выдавались ссылки вида site.ru/?p=123. Следовательно, если закрыть от индексирования ссылки с динамическими параметрами, то от индексирования будет закрыт весь сайт целиком. Да, можно там же в robots.txt прописать исключения, но в этих исключениях в будущем можно очень легко запутаться.
Также техническими дублями можно считать:
http://site.xyz
https://site.xyz
http://site.xyz
http://site.xyz/
http://site.xyz
http://www.site.xyz
В этом случае самым правильным решением будет настройка переадресации с кодом ответа 301. Обратите внимание, что для каждой страницы настраивать редирект нет необходимости – можно задать ряд «универсальных» правил, которые будут работать для любых документов.
Технические ошибки самого движка. Например, если неправильно прописать относительную ссылку, то вполне может получиться вот такая история:
site.ru/tools/tools/tools/…/…/… В нашем примере tools повторяется… скажем так – не один раз. Такое явление принято называть «зацикливанием».
Возможен и другой вариант.
Например, Вы находитесь на странице site.ru/tools/page1, Вы кликаете на неправильно сформированную ссылку и вместо site.ru/tools/page2 попадаете на адрес site.ru/tools/page1/tools/page2.
И тут уже всё зависит от настроек сайта. За счет таких ошибок может дублироваться либо главная страница, либо любые страницы сайта.
Лечение тут возможно только одно – ручное исправление допущенных ошибок + настройка переадресации на страницу 404, если генерируется битая ссылка.
Чем опасны дубли страниц на сайте?
Итак, мы разобрались с тем, какие виды дублей существуют, а также выяснили, как лечить сайт. Теперь расскажем о том, что может произойти, если оставить всё как есть, т.е. отказаться от лечения.
Во-первых, дубли (причем любые) снижают эффективность расхода краулингового бюджета (т.е. лимита документов, которых поисковый робот может обойти за одно посещение). Согласитесь, какой смысл сканировать одну и ту же страницу по 2-3-4 раза? Правильно – никакого. И если краулинговый бюджет составляет, скажем, 100 страниц, то по факту робот может обойти штук 40-50-60, а всё остальное вполне может оказаться дублями.
Во-вторых, поисковая система может прийти в замешательство, увидев две абсолютно идентичные страницы. Т.е. реализуется та самая история с ослом и двумя одинаковыми морковками, находящимися на одинаковом от осла расстоянии. Если же дубли будут склеены с помощью 301 редиректа или rel="canonical" – вопрос решается сам собой.
В-третьих, за счет затруднённого индексирования поисковая система может пессимизировать сайт, либо даже наложить фильтры - Панда (от Google) и/или АГС, он же АнтиГовноСайт (от Яндекса).
В-третьих, понижается процент уникальности текста. В современном SEO это не критично, однако, свой неприятный «бонус» дать всё еще может.
Как найти дубли страниц
Способов поиска дубликатов предостаточно, однако, ни один из них не является совершенным. Поэтому рассмотрим несколько способов.
Способ 1 – расширенный поиск Google.
Способ «топорный», а потому подходит только тем сайтам, у которых очень мало страниц.
Шаг 1: в поисковую строку прописываем site: и без пробела прописываем Ваш домен. Это необходимо для того, чтобы получить полный список проиндексированных страниц. Далее Вам нужно просто просматривать поисковую выдачу, т.е. выискивать дубли вручную.
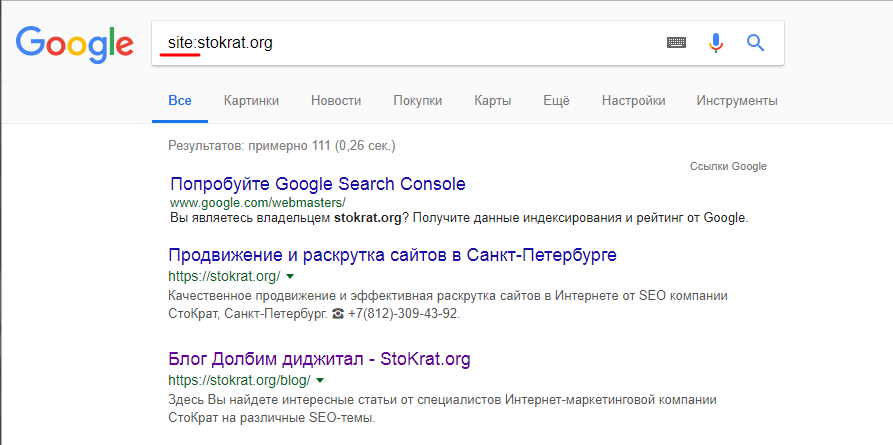
Шаг 2: вместе с именем домена указать еще и адрес страницы. Если будут дубли с динамическими параметрами – поисковая система Вас об этом обязательно уведомит. В данном случае дублей нет:
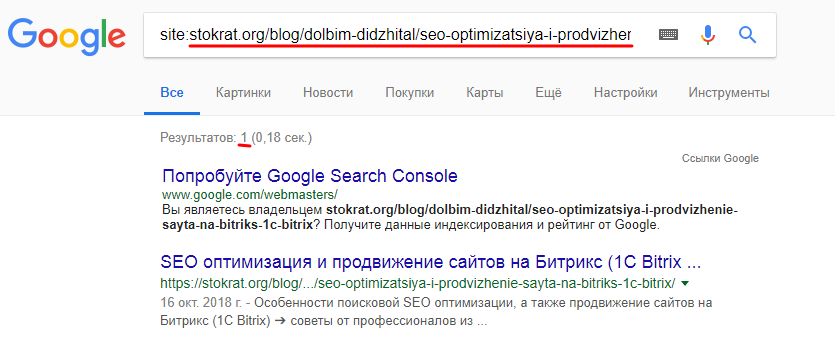
А вот в этом – есть: совпадает Title, Description, да и адреса отличаются только тем, что в одном https:// указан, а во втором – нет.
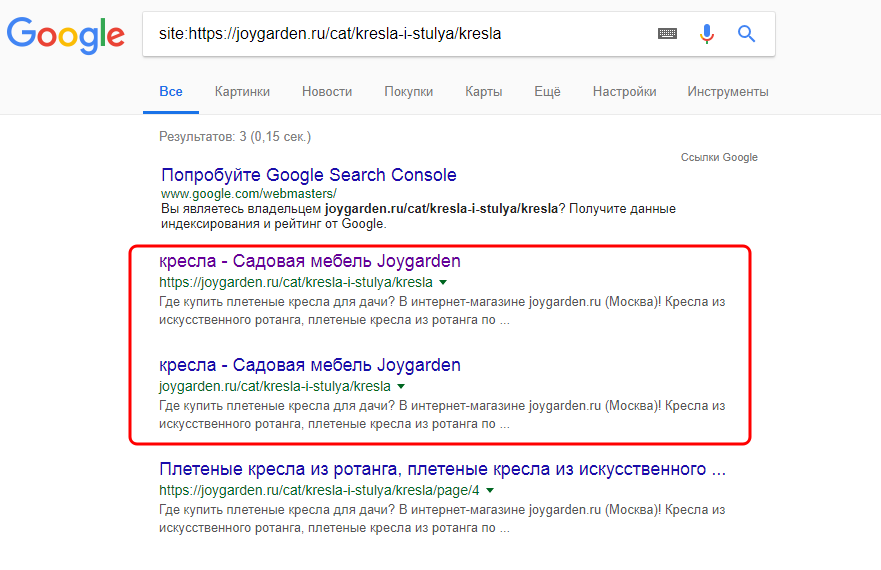
Справедливости ради стоит отметить, что при клике по нижнему адресу (который без https) происходит переадресация на адрес, в котором https уже прописан. Следовательно, дубли уже склеены. Однако, поисковая система их почему-то всё еще индексирует. В этом случае необходимо зайти в Google Search Console и запросить удаление нижнего адреса из индекса – он там больше не нужен.
Способ 2 – сканирование сайта с помощью программы XENU (Xenu Link Sleuth). С помощью данной программы можно выявить полные дубли страниц сайта. Однако, данный метод тоже не совершенен, поскольку программа НЕ сканирует контент – она ограничивается только мета-тегами. Именно поэтому данная методика НЕ позволяет выявить неполные дубли.
Шаг 1 – File -> Check URL (или нажать комбинацию клавиш Ctrl+N)
Шаг 2 – указываете доменное имя Вашего сайта, нажимаете ОК и ждёте окончания сканирования.

Шаг 3 – сортируете Title по алфавиту и смотрите, где есть точные совпадения. Каждое такое совпадение необходимо проверять вручную. Например, в случае с интернет-магазинами это могут быть разные страницы одного и того же раздела.
Также имейте в виду, что изображения тоже могут сопровождаться тегами.
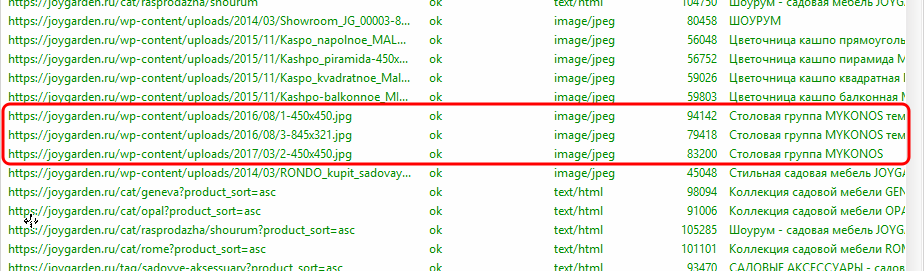
Способ 3 – сканирование сайта с помощью программы Screaming Frog SEO Spider.
Если коротко, то данный способ является аналогом предыдущего, за исключением одного важного момента – Screaming Frog предоставляет возможность отделить картинки от страниц. Следовательно, Вам придется просматривать гораздо меньшее количество строк.
Способ 4 – Google Search Console, она же Google-вебмастер.
Заранее предупреждаем, что для использования данного способа:
- Вы должны иметь свой личный кабинет в Google Search Console;
- Ваш сайт должен быть зарегистрирован в Вашем кабинете;
- должны быть подтверждены права на сайт;
- даже после этого способ будет доступен не сразу.
Сам же способ следующий:
1) заходите в «Вид в поиске» – «Оптимизация HTML» и смотрите, что да как.
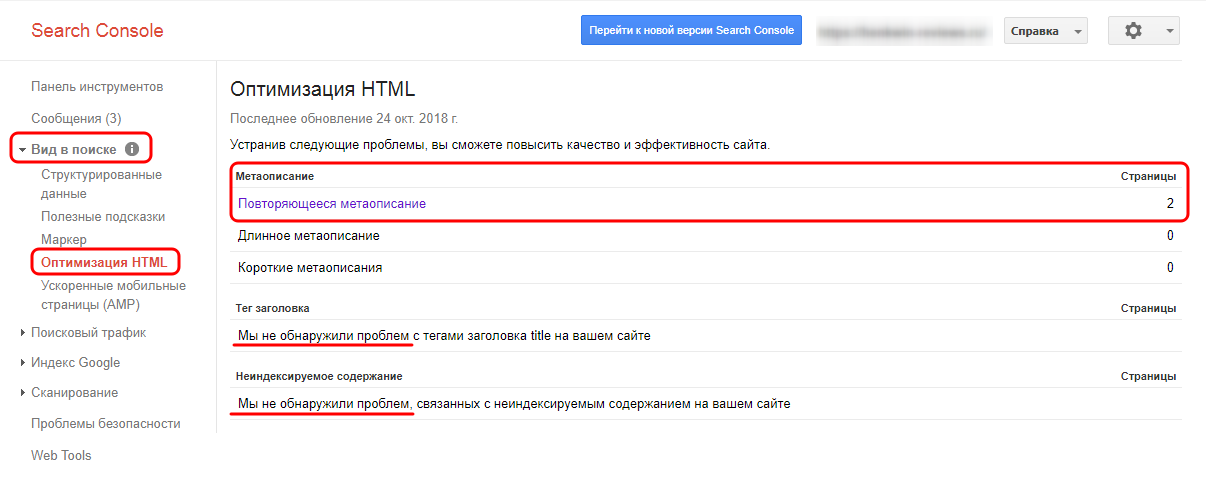
В данном случае дублей нет, однако, есть документы с повторяющимся описанием.
2) Система подскажет, что и где у вас повторяется. Поскольку в данном примере у нас повторяются описания – туда и заходим. В данном случае у нас описания повторяются на главной странице и в одной из статей.
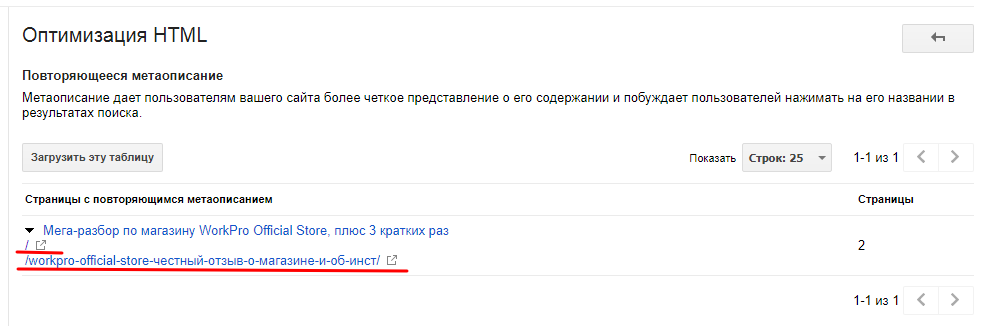
Следовательно, в данном примере информация о полных дублях не подтвердилась, а частичное копирование материалов на главную страницу – это для блогов нормально (пример уже приводился).
Способ 5 – онлайн-сервис Serpstat.
Сервис позволяет производить быстрый технический аудит сайта. Если коротко, то сервис выискивает не дубли страниц, а дублирующиеся мета-теги. Т.е. схема в целом мало отличается от Xenu и Screaming Frog.
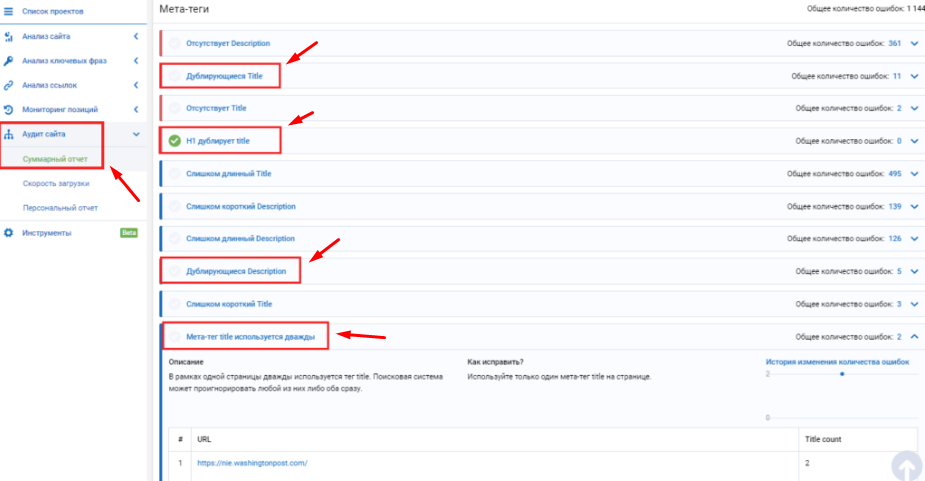
Способ 6 – онлайн-сервис SeoTo.Me.
Очень крутой сервис, с помощью которого можно найти как полные, так и неполные дубли.
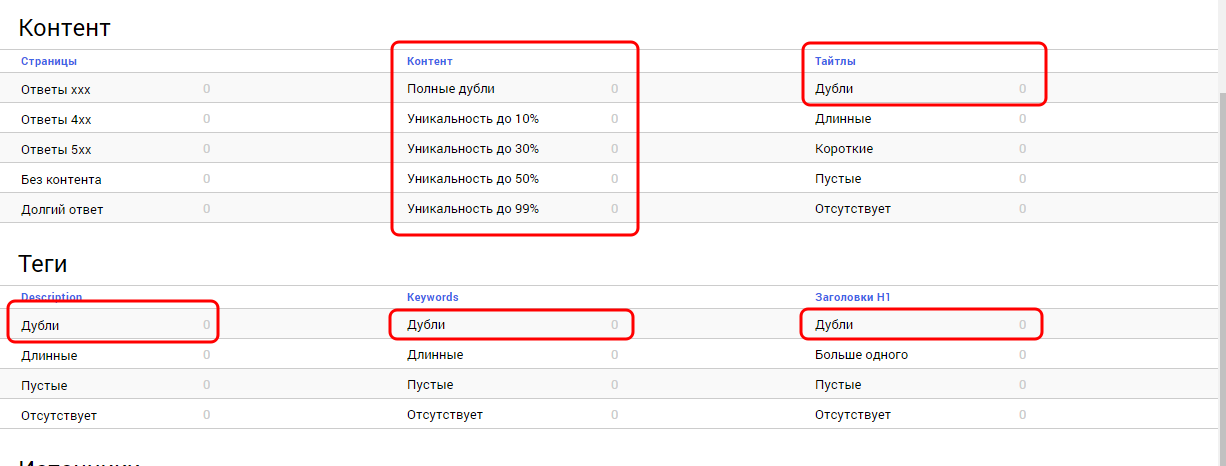
Сервис условно бесплатный. В бесплатном режиме он предоставляет не более 30% информации. Т.е. если на Вашем сайте было найдено 100 дублей, то сервис покажет не более 30. В платном режиме (500р/мес за 1 сайт) данное ограничение снимается.
Тем не менее, сайт сканируется полностью как в платном, так и в бесплатном режимах. Следовательно, количество дублей Вы в любом случае узнаете.
Внешние дубли
Это особый вид дублей. В народе этому виду уже давно придуман синоним – воровство. Проблема в том, что доказать поисковым системам авторство контента иногда бывает крайне проблематично. Как следствие, Ваш сайт может быть пессимизирован в выдаче даже в том случае, если контент украли у Вас.
О том, что делать в таких ситуациях, у нас уже есть отдельная статья [https://stokrat.org/blog/dolbim-didzhital/kak-proverit-unikalnost-teksta/], поэтому на данном пункте мы останавливаться не будем.
Выводы
Итак, мы выяснили, что дубли могут быть как полными, так и частичными, выяснили, что польза от дублей может быть только в одном случае – если в интернет-магазине одна и та же карточка продублирована в 2-3 раздела. Также мы разобрались с тем, как оперативно найти дубли страниц по заголовкам Title и H1.
Да, мы не спорим, поиск дублей по заголовкам Title и H1 – это далеко не идеальный метод, однако, справедливости ради стоит отметить, что наличие двух страниц с совпадающими мета-тегами – это не норма даже в том случае, если контент на этих страницах отличается.
Как часто следует проверять сайт на дубли?
Четкого ответа на данный вопрос дать нельзя. С одной стороны, чем чаще – тем лучше. Однако, проверять сайт на дубли каждый день, каждую неделю, даже каждый месяц – это уже перебор. В большинстве случаев хватает одной проверки в квартал или даже одной проверки в полугодие, а то и в год.





